You can see the queries showed up in Hyperdrive Analytics (while the worker was using hyperdrive)
You can see the queries showed up in Hyperdrive Analytics (while the worker was using hyperdrive)
 K
K K
K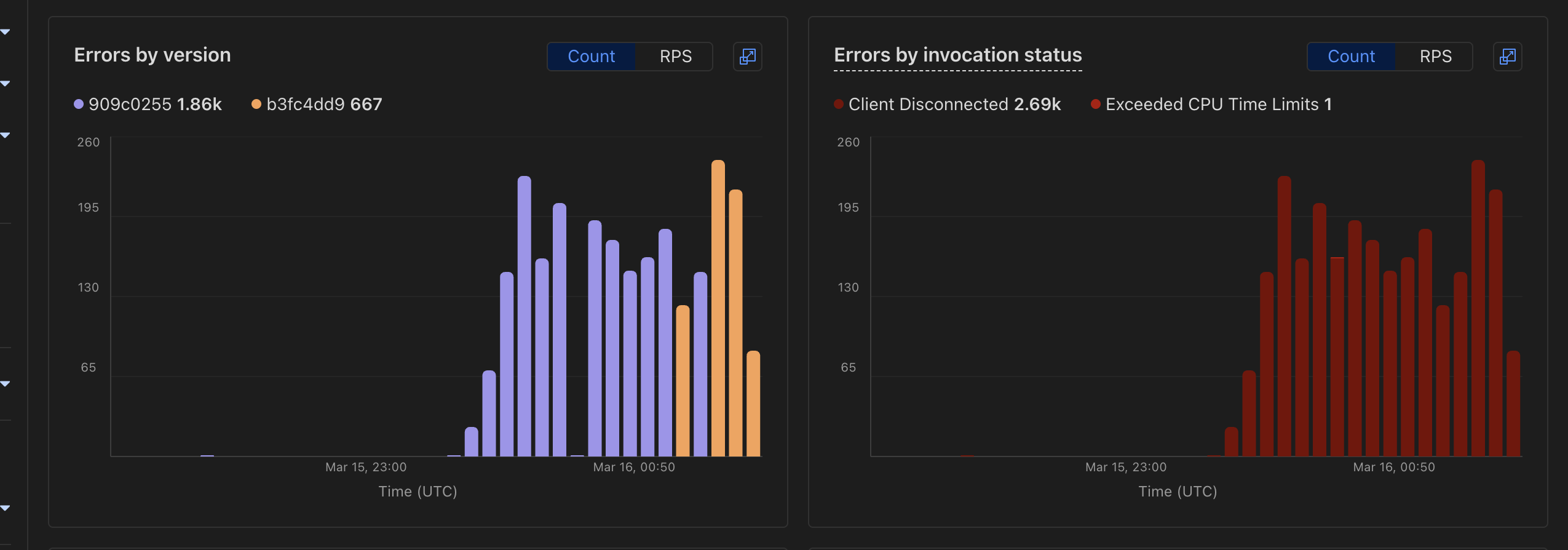 K
K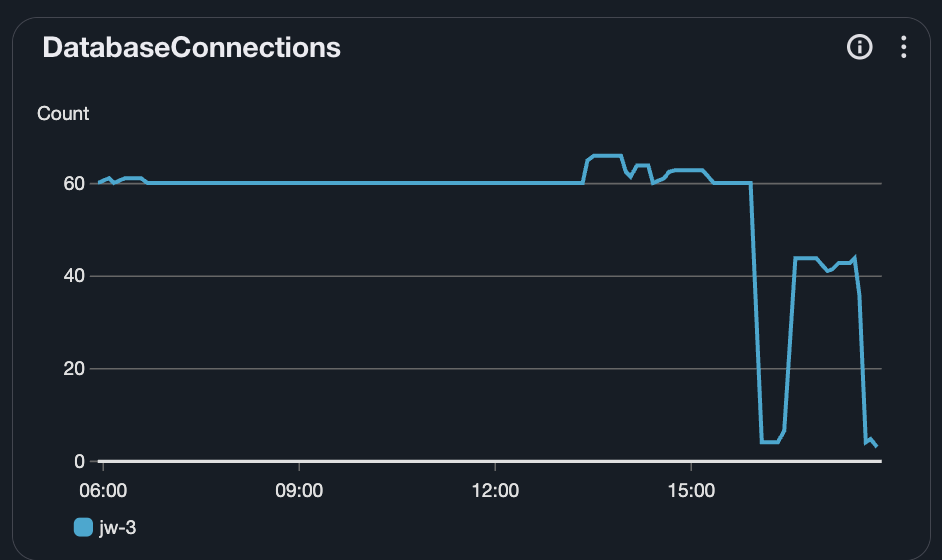 K
K AKK
AKK IK
IK AKIIAA
AKIIAA OOAAAKAA
OOAAAKAA S
SCONNECTION_CLOSED YKAAAAAAA
YKAAAAAAA T
T AA
AA K
K E
E I
I DA
DA






