@Kathy | Browser Rendering PM Ah fair, it's related to "context caching" at Google / Vertex AI. For
@Kathy | Browser Rendering PM Ah fair, it's related to "context caching" at Google / Vertex AI. For huge contexts and long repeated runs with the same context this can siginificantly speed up inference and cost savings. https://ai.google.dev/gemini-api/docs/caching?lang=rest.
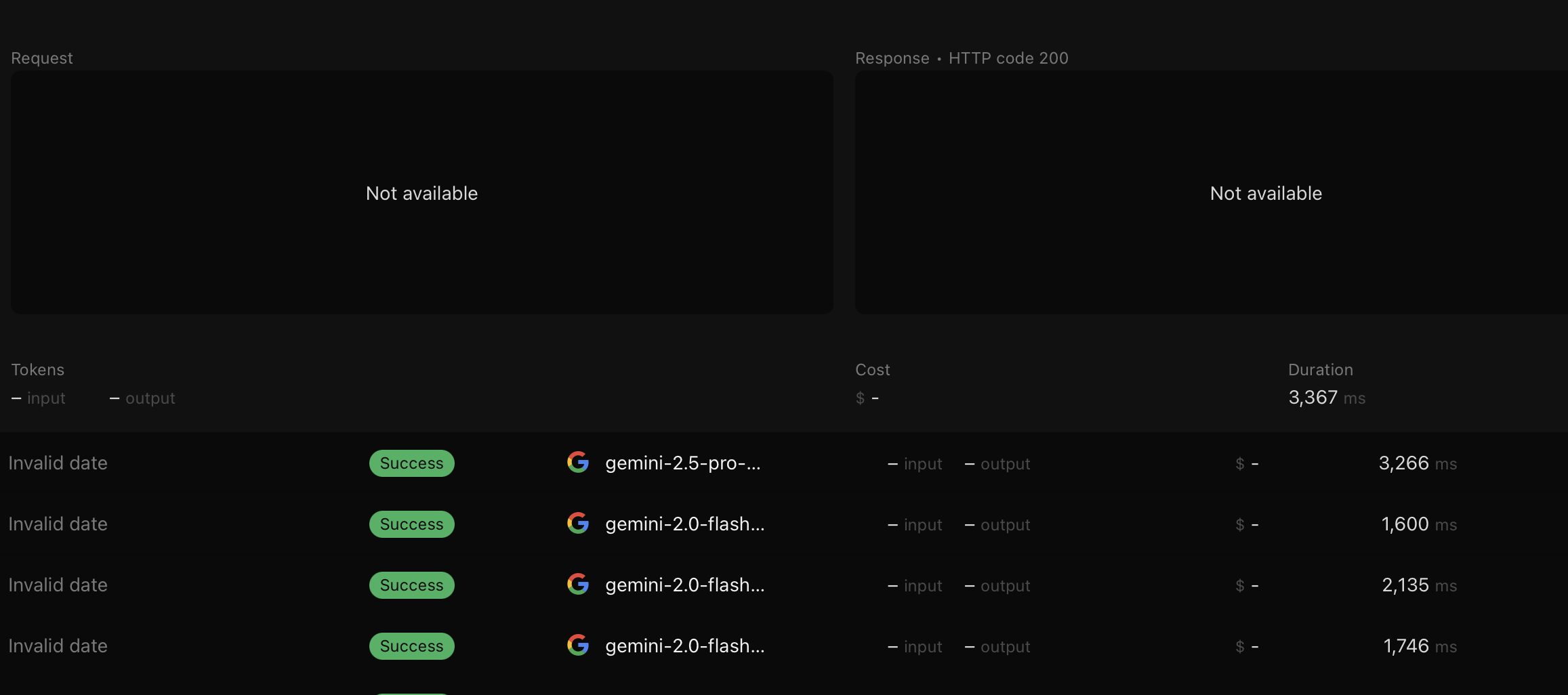
The problem I'm having here is that Google is taking an increasingly long time to more context you give it to create this Context Cache. We often hit 2+ minutes for bigger context (20/30+ PDF files, some of them 100+ pages, which on their side I think are being transformed into images, and then into tokens).
The problem I'm having here is that Google is taking an increasingly long time to more context you give it to create this Context Cache. We often hit 2+ minutes for bigger context (20/30+ PDF files, some of them 100+ pages, which on their side I think are being transformed into images, and then into tokens).
Google AI for Developers
Learn how to use Context Caching in the Gemini API