Hey, so coming back with some more (correct) metrics now. Firstly, these are significantly improved
Hey, so coming back with some more (correct) metrics now.
Firstly, these are significantly improved because we made a change to always query D1, regardless of if the response is cached in the CDN, this seems to keep D1 significantly warmer, and our response times are much better in general than before we added this.
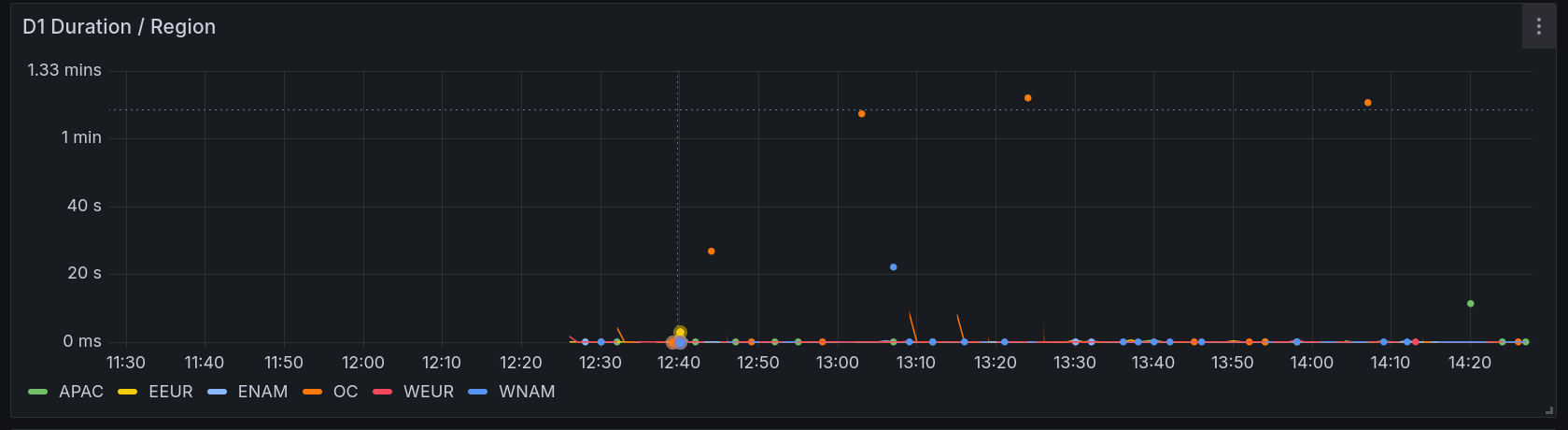
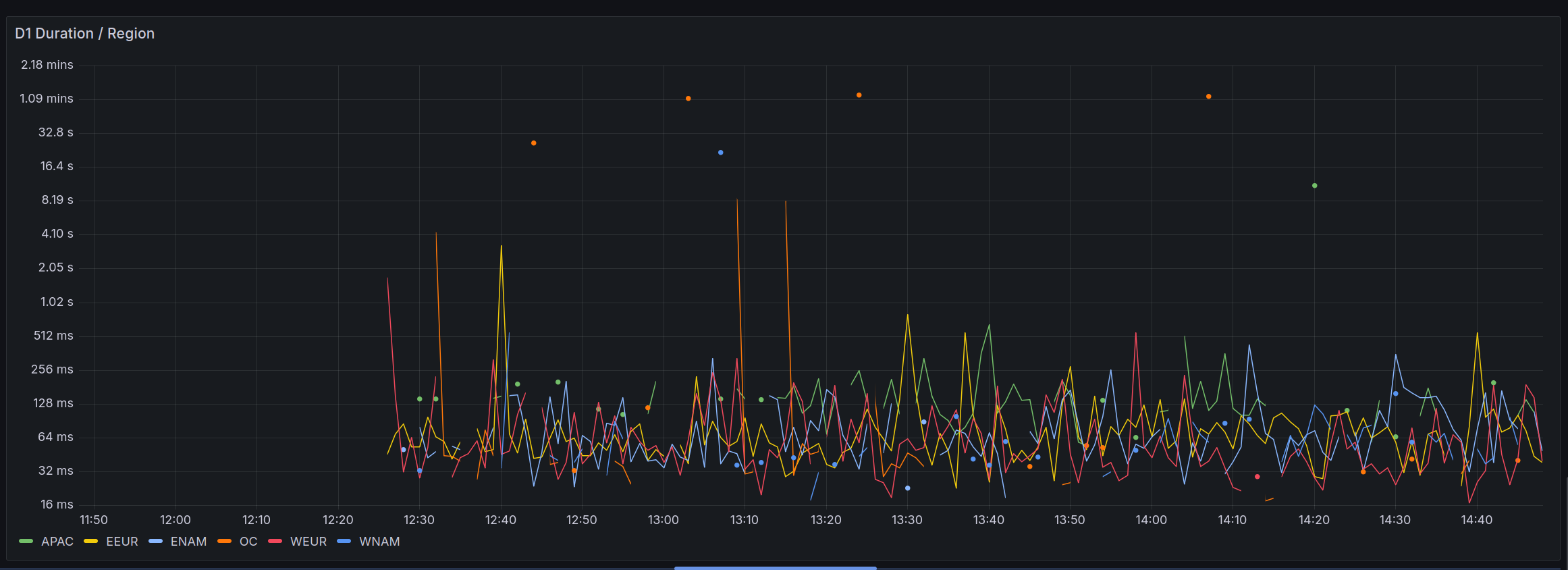
Now, onto the data. As I said before, errors are basically gone now, however we still get latency spikes. I've drilled into this pulling some data split by region, this is specifically metrics around the D1 call from the worker.
As you can see (in this 95th percentile graph), OC is our worst offender here, it occasionally has significant spikes in latency, sometimes going over a minute.
It is currently nighttime there, so we don't have many requests going through for OC, however a minute is still significant.
As we said, the upcoming changes around bypassing the replica when it's booting up would help this for sure, but a minute still seems pretty excessive
Firstly, these are significantly improved because we made a change to always query D1, regardless of if the response is cached in the CDN, this seems to keep D1 significantly warmer, and our response times are much better in general than before we added this.
Now, onto the data. As I said before, errors are basically gone now, however we still get latency spikes. I've drilled into this pulling some data split by region, this is specifically metrics around the D1 call from the worker.
As you can see (in this 95th percentile graph), OC is our worst offender here, it occasionally has significant spikes in latency, sometimes going over a minute.
It is currently nighttime there, so we don't have many requests going through for OC, however a minute is still significant.
As we said, the upcoming changes around bypassing the replica when it's booting up would help this for sure, but a minute still seems pretty excessive