Durable Objects not suitable for this?
Durable Objects not suitable for this?

 D
D A
A TDDTA
TDDTA D
D M
M T
T
 O
O A
A A
A
 ZA
ZA SASASSAS
SASASSAS A
Apgpostgrespg ZAZAA
ZAZAAnpx wrangler dev --remote--remote
 JA
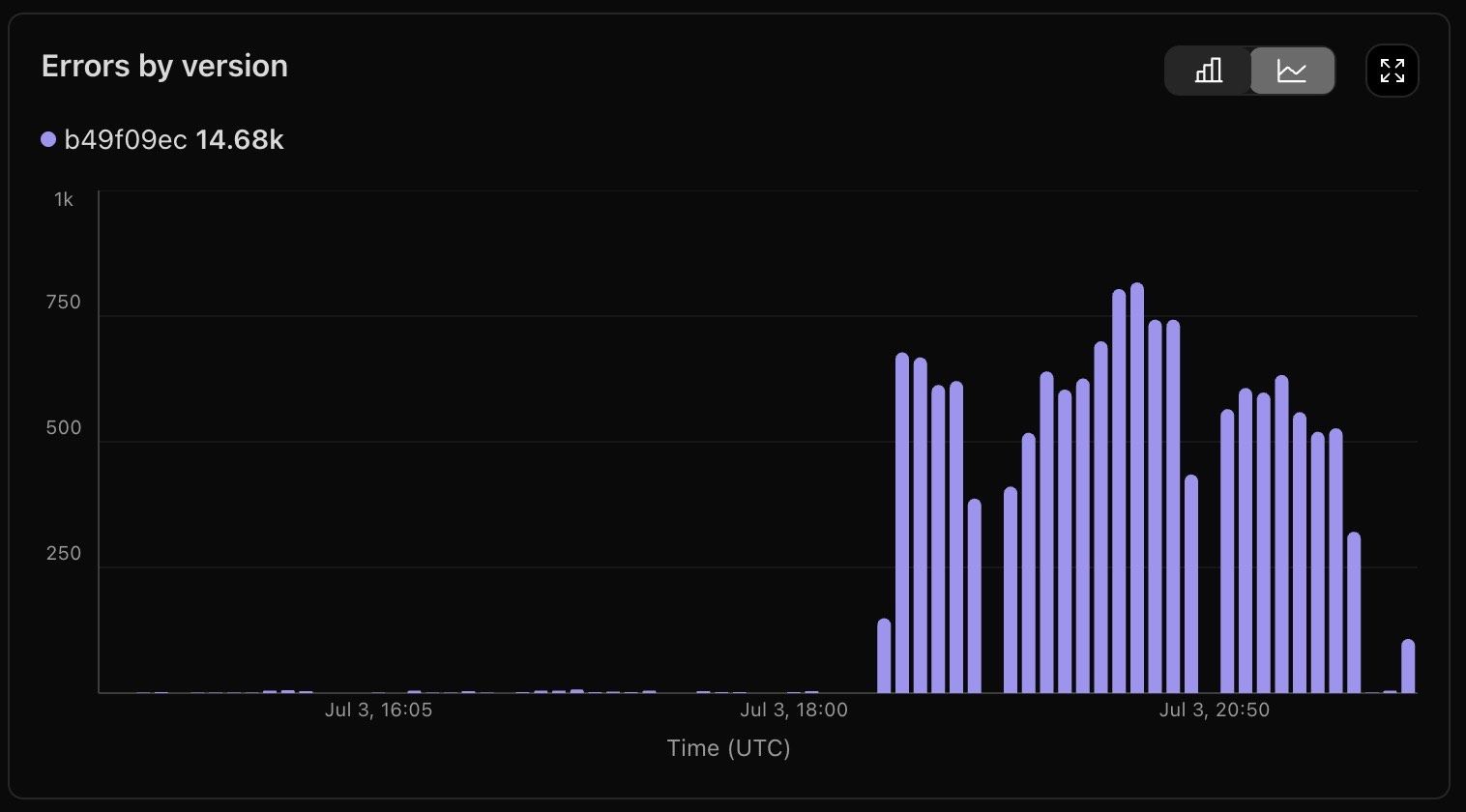
JA https://screen.bouma.link/XjBnMv39lxpkny2HfM3cAASAA
https://screen.bouma.link/XjBnMv39lxpkny2HfM3cAASAA the notification of the changelog triggered me to look. Worker falls through to the origin though, so no biggy in this case for me)AA
the notification of the changelog triggered me to look. Worker falls through to the origin though, so no biggy in this case for me)AA