oh sorry I thought you were talking about a different dataset. I'm going to use this dataset and try
oh sorry I thought you were talking about a different dataset. I'm going to use this dataset and try it out using massed compute now.
 UU
UU E
E FFFFFFFFEFFFFFFEFFF
FFFFFFFFEFFFFFFEFFF
 J
J FFU
FFU The finetuned checkpoint is about 23gb, is there a way to reduce the size without losing the quality?FFUFEEFFFFEFFFFEFUU
The finetuned checkpoint is about 23gb, is there a way to reduce the size without losing the quality?FFUFEEFFFFEFFFFEFUU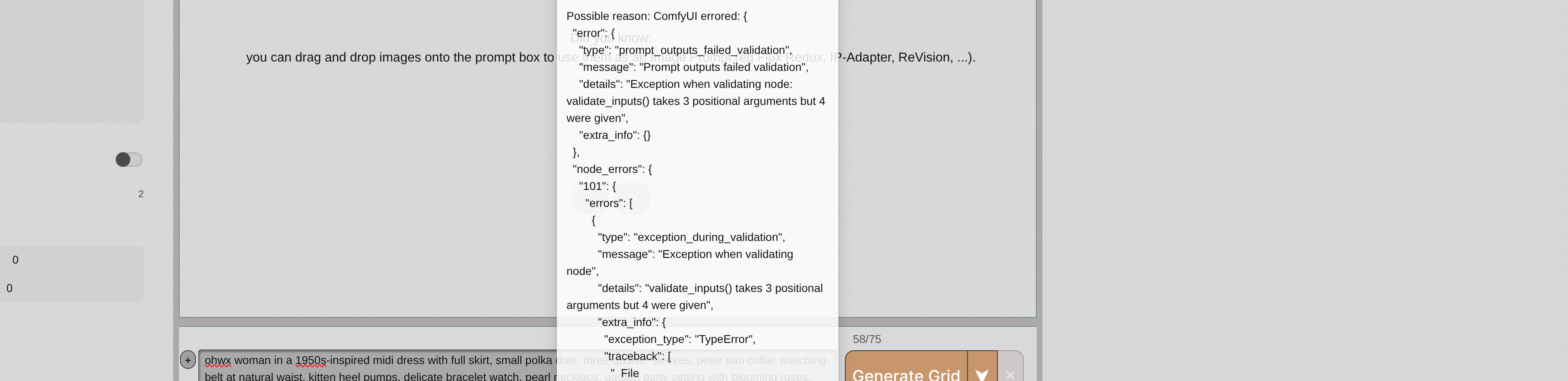 FFU
FFU


