ChatGPT is incorrect. Workers for Platforms allows you to dynamically create Workers (and therefore
ChatGPT is incorrect. Workers for Platforms allows you to dynamically create Workers (and therefore bind Vectorize DBs to those Workers) via an API.

 II
II K
K V
V

 B
B D
D--experimental-vectorize-bind-to-prodIDembedding_values = [32.4, 74.1, 3.2, ...];
//sampleVectors_1 : (Same embedding value, same namespace, only Vector-ID differ)
const sampleVectors_1: Array<VectorizeVector> = [
{ id: "1", values: embedding_values, namespace: "text", },
{ id: "2", values: embedding_values, namespace: "text", },
] Y
Y G
G Vectorize update:
Vectorize update: 
 ZZ
ZZ SY
SY NV
NV Z
Zvitest-pool-workersVectorizeIndex.query()VECTOR_QUERY_ERROR: STATUS + 500 MR
MR V
V A
A
 Z
Z
 AZA
AZAVectorizeIndexupsertPromise<VectorizeVectorMutation>mutationId C
C C
C P
P S
S M
MdeleteByIdsdeleteByIds YMCCCC
YMCCCCdeleteById EV
EV V
V D
D PP
PP SD
SD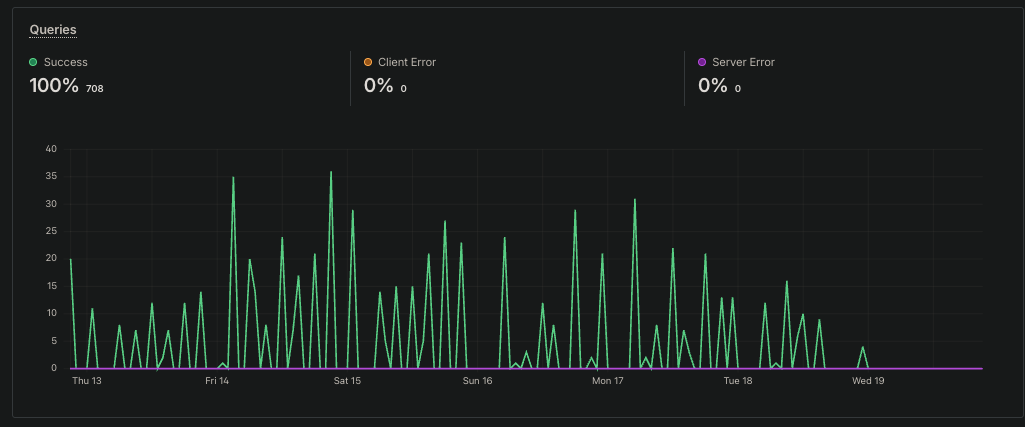
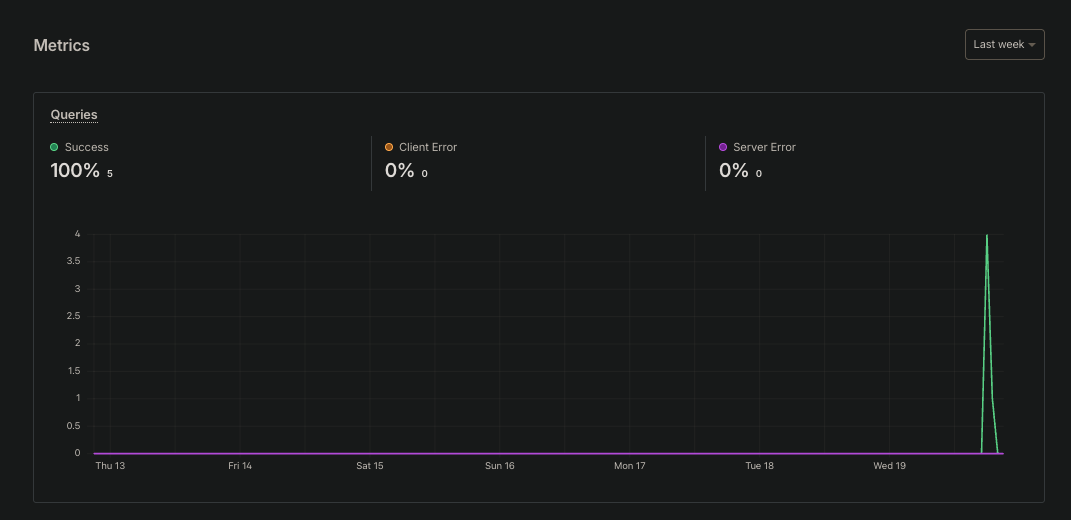 P
Pembedding_values = [32.4, 74.1, 3.2, ...];
//sampleVectors_1 : (Same embedding value, same namespace, only Vector-ID differ)
const sampleVectors_1: Array<VectorizeVector> = [
{ id: "1", values: embedding_values, namespace: "text", },
{ id: "2", values: embedding_values, namespace: "text", },
]workerd/io/worker.c++:2169: info: uncaught exception; source = Uncaught (in promise); stack = Error: VECTOR_QUERY_ERROR: Status + 500
at VectorizeIndexImpl._send (cloudflare-internal:vectorize-api:185:23)
at VectorizeIndexImpl.queryImplV2 (cloudflare-internal:vectorize-api:205:21)
at VectorizeIndexImpl.query (cloudflare-internal:vectorize-api:45:20)export const search = base
.route({ method: 'POST', path: '/ai/vectors/search' })
.input(
z.object({
embeddings: z.array(z.number()),
topK: z.number().optional().default(10),
filter: z.record(z.string(), z.any()).optional(),
})
)
.output(vectorizeMatchesSchema)
.handler(async ({ input, context }) => {
const options: VectorizeQueryOptions = {
returnMetadata: true,
topK: input.topK,
};
if (input.filter) {
options.filter = input.filter;
}
const results = await context.env.VECTORIZE.query(input.embeddings, options);
return vectorizeMatchesSchema.parse(results);
}); return await client.ai.vectors.search({
embeddings: embeddings.data[0] ?? [],
topK,
filter: {
userId: {
$eq: userId,
},
},
});
}