
Welcome to the official Cloudflare Developers server. Here you can ask for help and stay updated with the latest news
83,498Members
View on DiscordResources
Similar Threads
Was this page helpful?
 D
D T
TThe RPC receiver does not implement the method "run" SS
SSApiError: {"error":{"message":"error code: 524","code":524,"status":""}} CS
CS B
B H
H DHH
DHH CC
CC A
A TC
TC
 F
F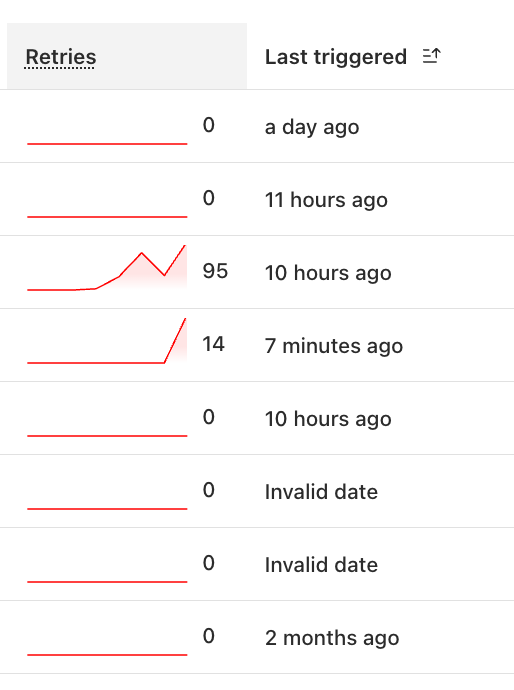 F
F
 B
B V
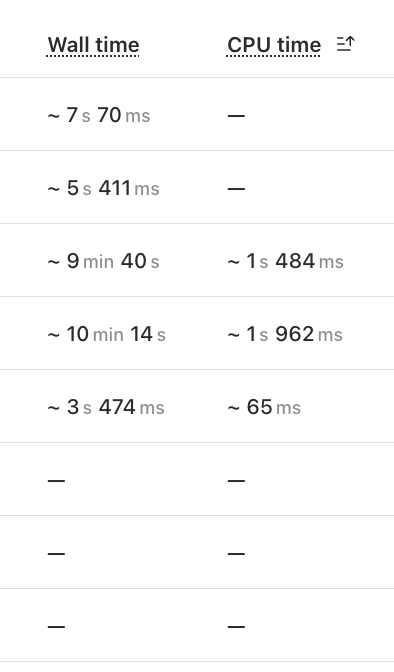
Vworkflows.api.error.internal_server [code: 10001]wrangler workflows ...wrangler publish K
K{ step-failed: 'blah-blah', timestamp: '' }onErrorWorkflow A
A A
AInternal Server Error
 JFB
JFB BF
BF
 D
D{retries:{limit:0}}wrangler deploytry/catch throw new NonRetryableError()Attempt failed due to internal workflows error I'm going to add a KV check to the start of the step, but am I missing something super obvious? Is there a recommended pathway for getting a step to only ever run once?
I'm going to add a KV check to the start of the step, but am I missing something super obvious? Is there a recommended pathway for getting a step to only ever run once? J
J JSJM
JSJM B
B V
V D
D Membership roles in "Organization Name": Contact account super admin to change your permissions.
Membership roles in "Organization Name": Contact account super admin to change your permissions. Token Permissions:VM
Token Permissions:VM N
N , If I have a workflow in progress (for example, currently at step 2 of 3), and I deploy a new version of the workflow that removes or changes step 3, what happens to the in-progress workflow?DD
, If I have a workflow in progress (for example, currently at step 2 of 3), and I deploy a new version of the workflow that removes or changes step 3, what happens to the in-progress workflow?DD N
N H
H
 sorry for the ping, but would really love to know your thoughts on this. It would be great to have the ability to handle fatal errors at the workflow level, rather than having to handle each step individually.H
sorry for the ping, but would really love to know your thoughts on this. It would be great to have the ability to handle fatal errors at the workflow level, rather than having to handle each step individually.Hstep.do.catch()neverthrow EV
EVoptions.globalFailureHandlerawait wf.complete;
console.log(await wf.output);const validationResult = await step
.do('validate', async () => {
// do some logic here
return { somedata: true };
})
.catch((e) => {
// handle your error here, and possibly re-throw it if you want it to be fatal
});const validationResult = await fromPromise(
step.do('validate', async () => {
// do some logic that could throw here
return { somedata: true };
}),
(e) => e,
).match(
(result) => result,
(e) => {
// handle your error here, and possibly re-throw it if you want it to be fatal
},
);






