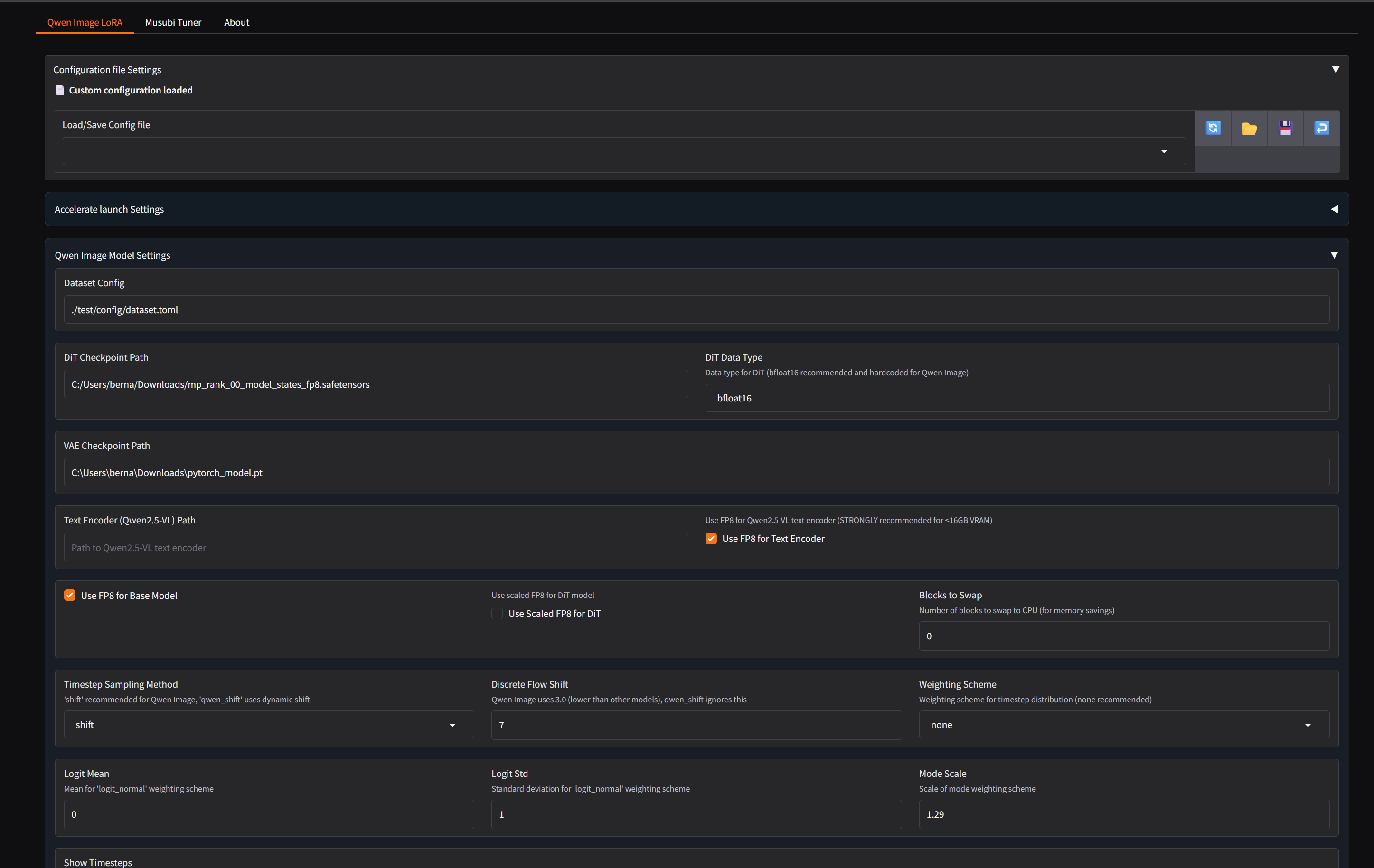
Just wanted to share an update: I've finished my new Qwen-Image LoRA training, and I'm really happy with the results! It's a huge improvement over my first attempt.
I think the new, advanced features in Musubi-Tuner made a massive difference. For this run, I used:
LoRA+ to make the training more efficient.
PyTorch Dynamo (inductor backend) to compile and optimize the model on the fly in WSL.
The qinglong_qwen sampler for a more intelligent learning process.
After the training was complete, I picked my top 3 favorite checkpoints. Then, instead of just choosing one, I merged them into a single, final model using the lora_post_hoc_ema.py script. This command averages the weights of the best LoRAs to create a more stable and higher-quality final version.
There's still some work to do on finding the best sampler and scheduler, but I'm very pleased with the outcome so far. The training took a bit longer than expected, around 4 hours on my RTX 4090, which was likely due to the initial, slow compilation phase of PyTorch Dynamo that needs time to warm up.
Here are a few example images generated with the final merged LoRA + 8stepLora.

 J
J A
A

 C
C S
S






 D
D S
S
 F
F