Hello Dr, do you think we will be able to do something similar to dreambooth style full finetune of
Hello Dr, do you think we will be able to do something similar to dreambooth style full finetune of qwen? Is this possible?
 筋
筋 JJ
JJ FFFF筋筋F筋筋筋F筋
FFFF筋筋F筋筋筋F筋 FFF
FFF FF筋筋FF筋FF筋
FF筋筋FF筋FF筋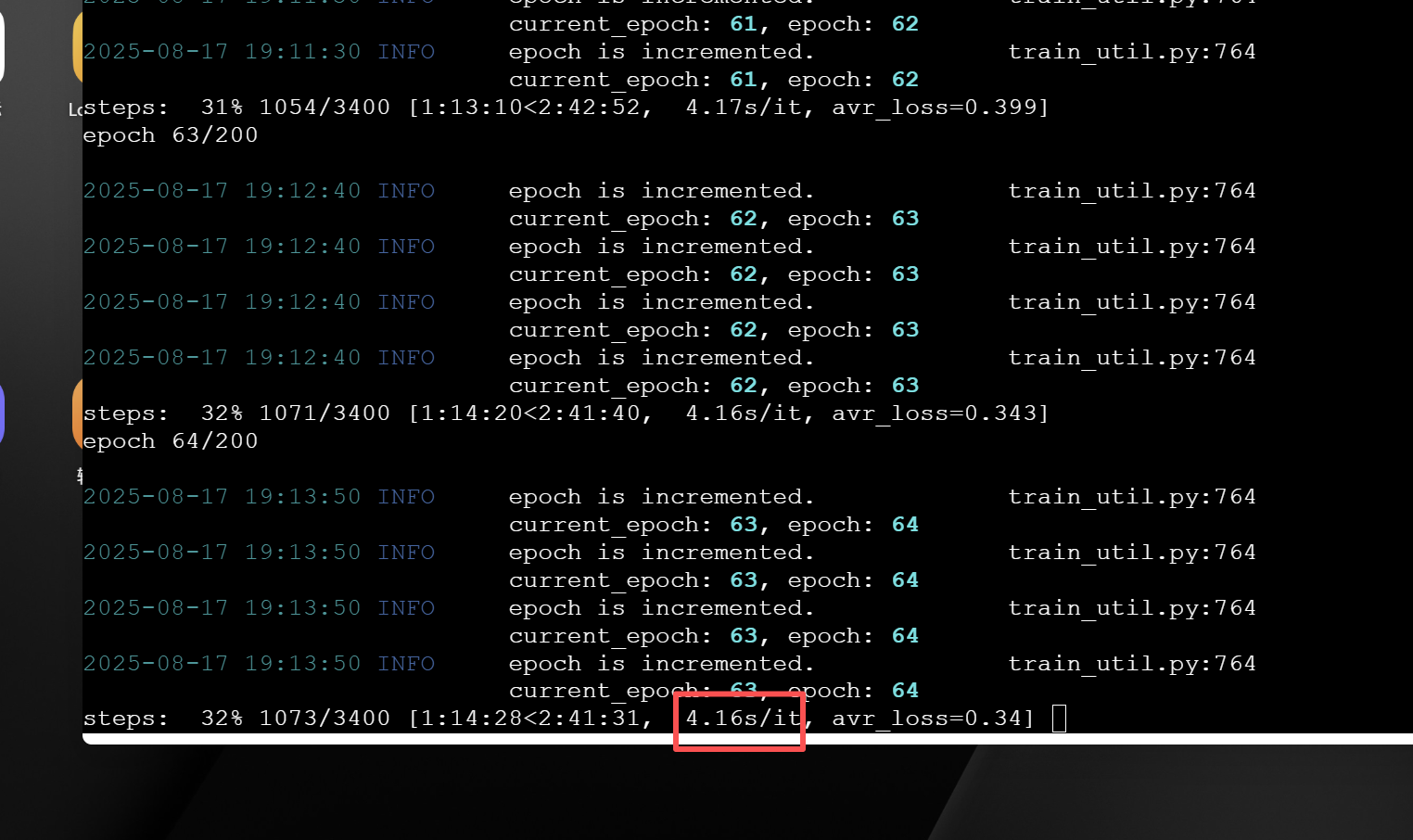 FFF
FFF TF
TF K
K TFF
TFF Z
Z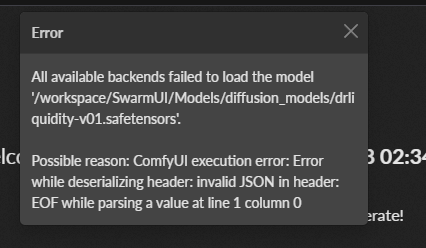 FFF
FFF S
S U
U
 S
S EJEJJE
EJEJJE




