We are having tons of D1 issues this morning. Anyone else?
We are having tons of D1 issues this morning. Anyone else?

 L
L O
O J
J M
M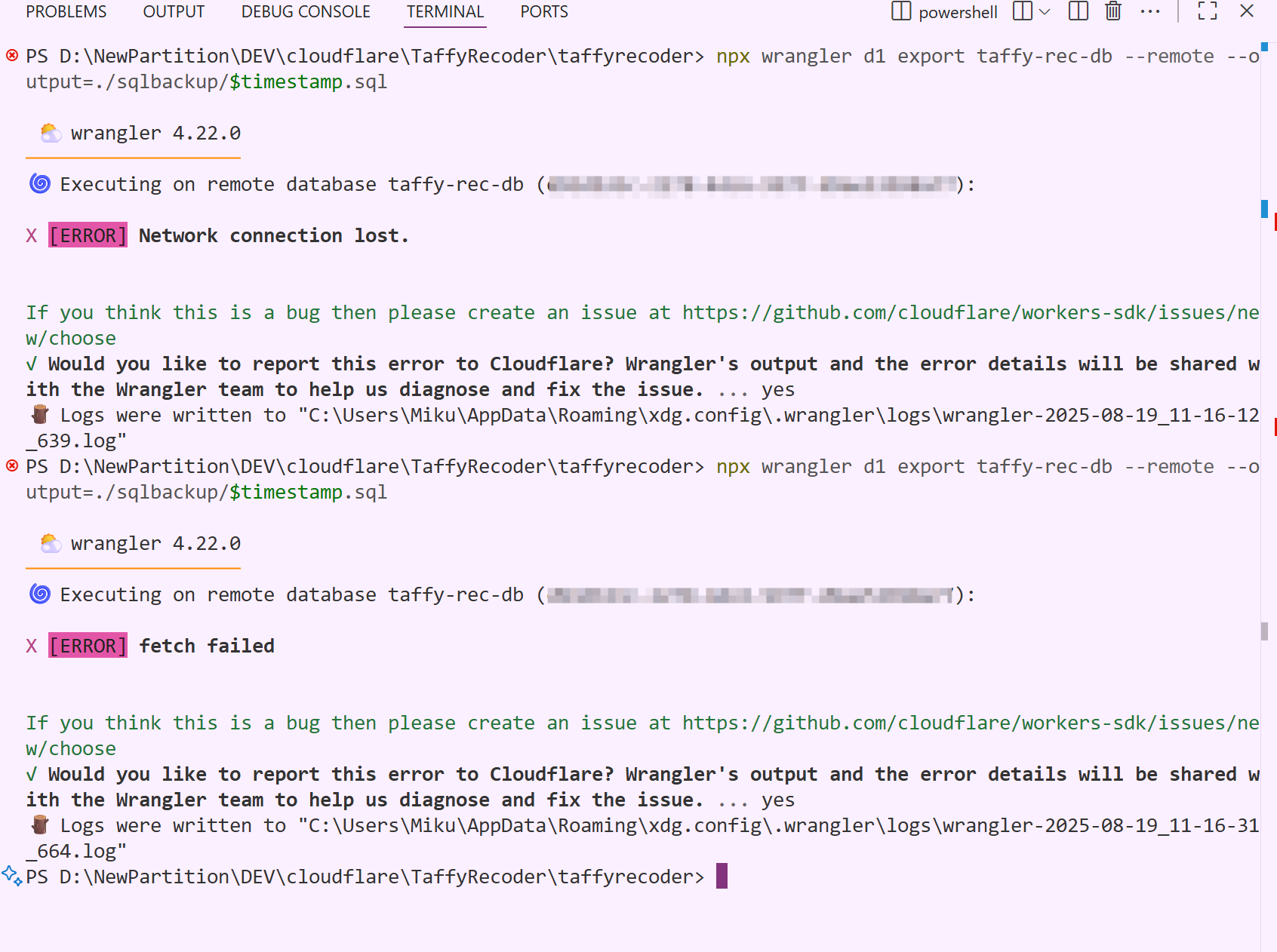
 G
G SL
SLbind() J
J
 TT
TT GLL
GLL LGMG
LGMG ADL
ADL DL
DL KDD
KDD I
I SL
SL MM
MM CMMCM
CMMCM S
SD1_ERROR TLTL
TLTL E
E TM
TM Home to Wrangler, the CLI for Cloudflare Workers® - cloudflare/workers-sdk
Home to Wrangler, the CLI for Cloudflare Workers® - cloudflare/workers-sdk LT
LT N
N├── packages/
│ ├── worker/
│ └── db/
└── apps/
└── app1/
└── app2/














