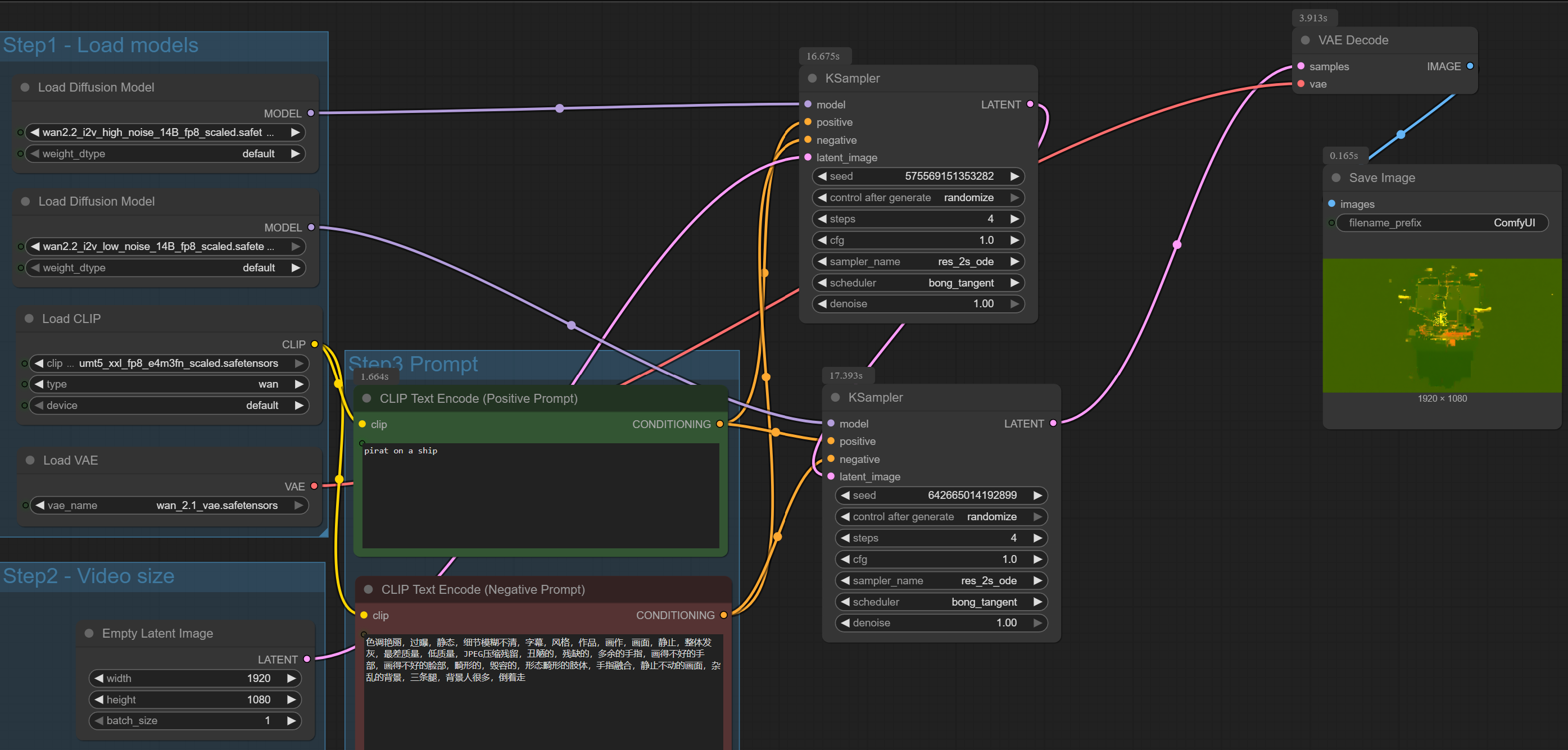
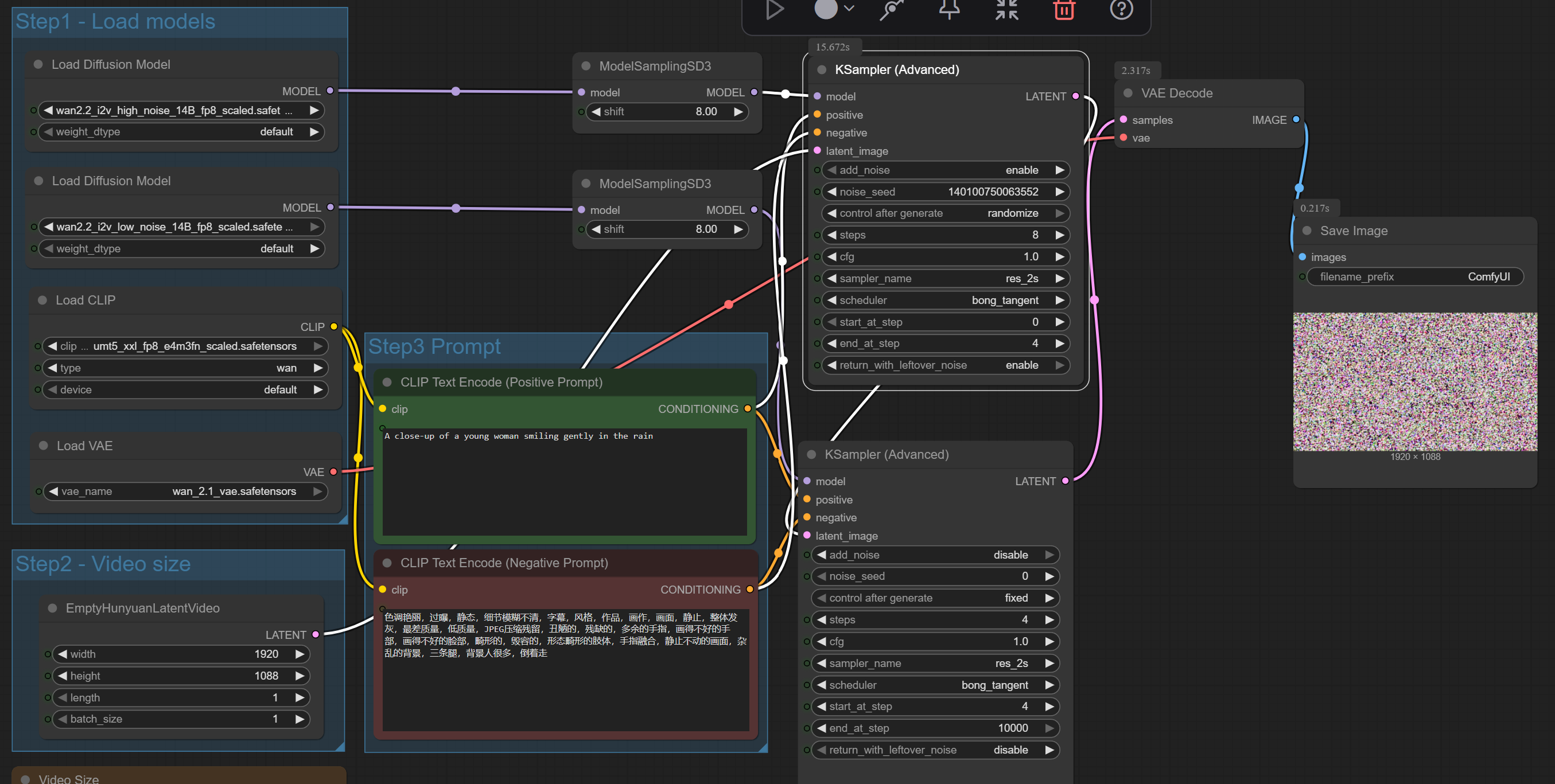
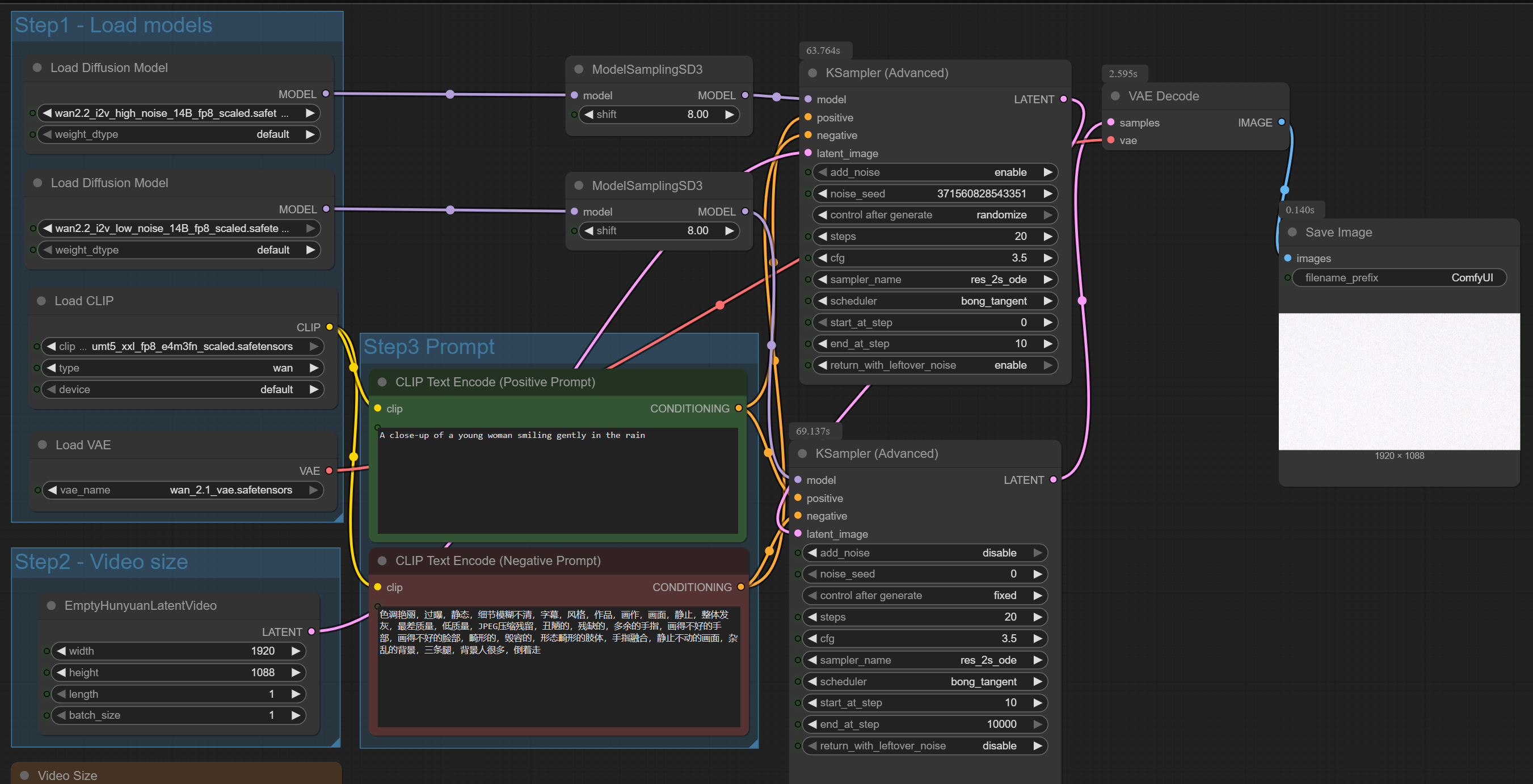
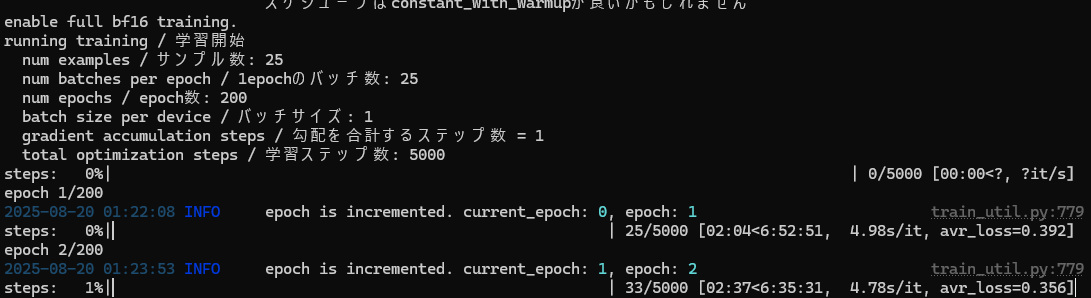
Hi Furkan, I want to confirm something about your captioning theory. For a small and very consistent
Hi Furkan, I want to confirm something about your captioning theory.
For a small and very consistent dataset (around 50 solid product photos on white background), is it still best practice to only use the token + class as caption (like CCCSNOOO bag), and let the images carry all visual attributes?
Or in such small homogeneous datasets, could adding more detailed captions (e.g. color, material, shape) actually help stabilize training with T5?
For a small and very consistent dataset (around 50 solid product photos on white background), is it still best practice to only use the token + class as caption (like CCCSNOOO bag), and let the images carry all visual attributes?
Or in such small homogeneous datasets, could adding more detailed captions (e.g. color, material, shape) actually help stabilize training with T5?