Yeah the DO is in Mel but request being routed through Perth
Yeah the DO is in Mel but request being routed through Perth
 1
1 P1
P1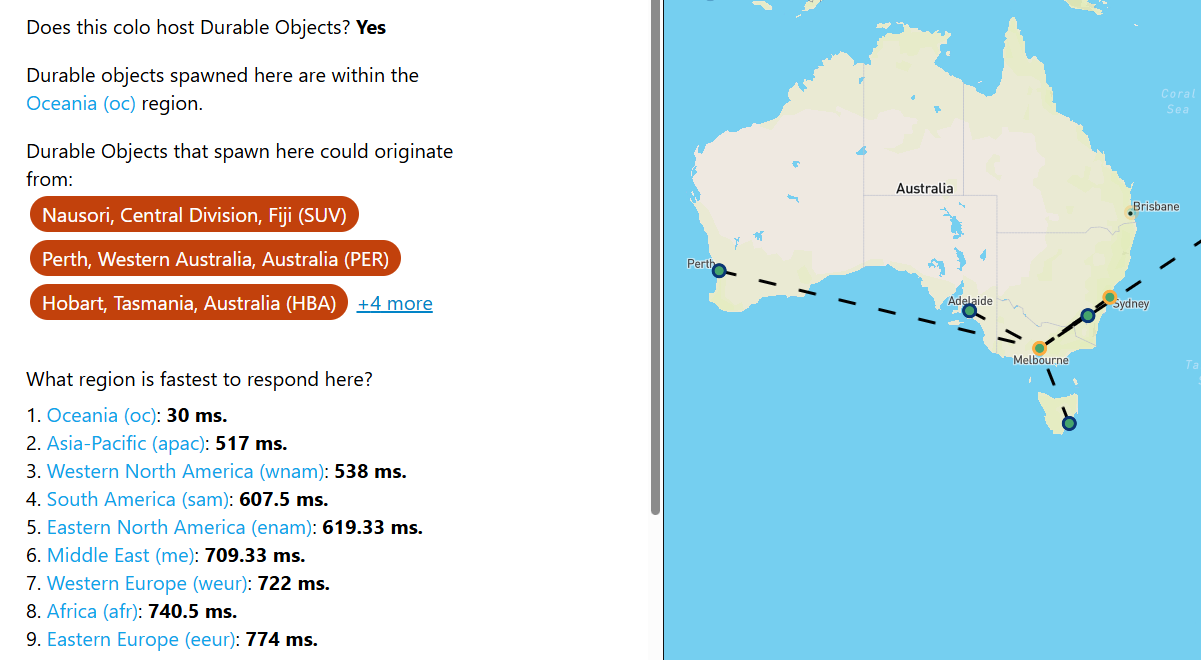 1PPP1
1PPP1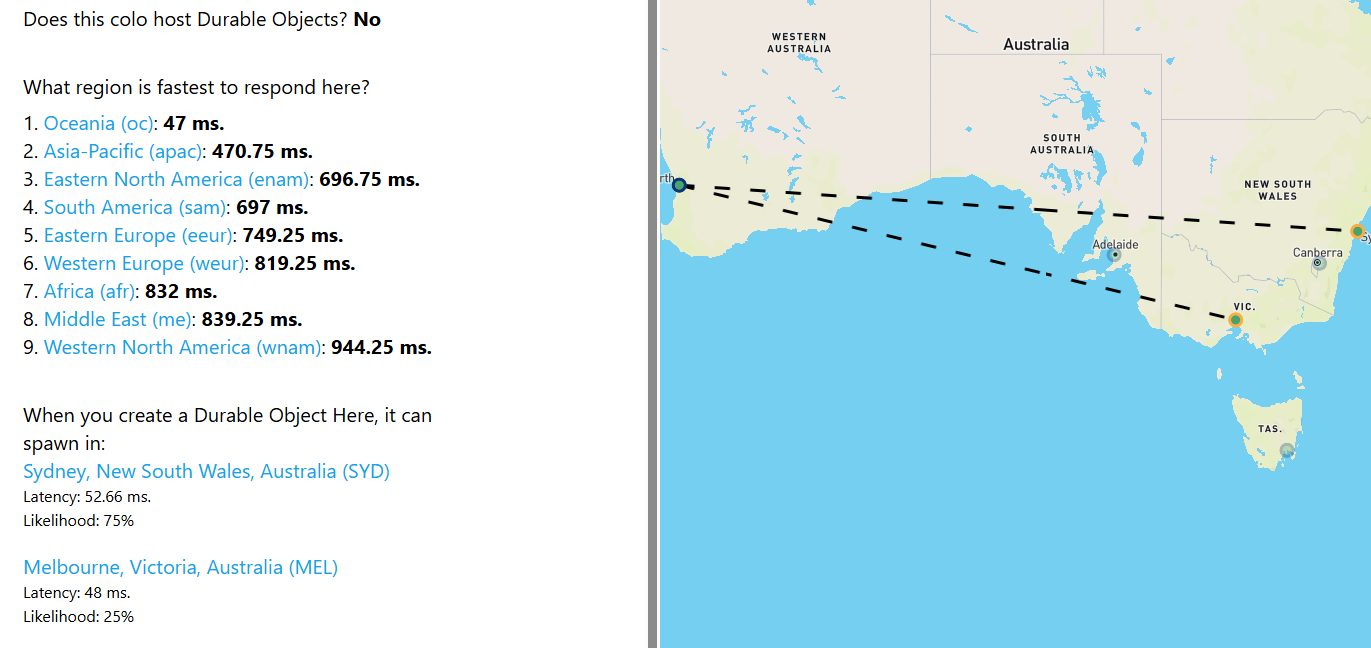 P11
P11 hopefully someone has seen me complaining and is fixing this as we speak1P
hopefully someone has seen me complaining and is fixing this as we speak1P
 L 1L1L
L 1L1L 111
111 N
N Y
Y M
M N1
N1name HNHNYHY
HNHNYHY LY
LY J
J NJLYL
NJLYL CYCLC it should automatically be disposed. Unsure about max or idle timeout. Good idea to have wrapper on calling side to do retries with backoffL
CYCLC it should automatically be disposed. Unsure about max or idle timeout. Good idea to have wrapper on calling side to do retries with backoffL2025deleteAll()routeDORequest







