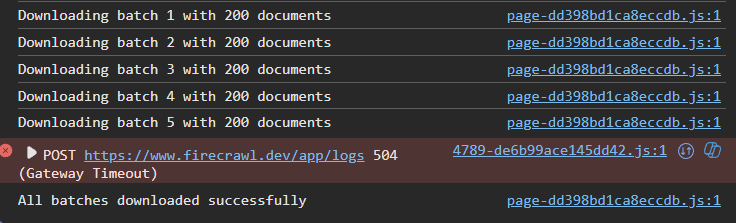
downloading large crawl from dashboard fails
How can you download a large crawl job's output (5k documents)? Doing it through the dashboard fails as it sometimes downloads the first part of it (in JSON or md formats) and others nothing, so how can we use the returns from these large jobs?
python sdk crawl endpoint run non stop and run me out of credit
aI was testing firecrawl for the following use case: scrape the website of a startup for their product
I notice that with this website in particular, despite setting a limit of 2, the endpoint run non stop until I reach my credit limit
app = FirecrawlApp(api_key=[MY_API])
crawl_status = app.crawl_url(...
Crawl job never stopping
so i am trying out firecrawl sdk for the first time as the playground worked very well. Getting confusing results.
1. this code just hangs and never prints the crawl_results:
```
print("CRAWLING")...
Change Tracking Cache TTL Rate Limiting Question (Free Tier)
Hey Firecrawl team! 👋
I'm building a system that needs to periodically check websites for changes (e.g., every 10 minutes) and then notify users if something is different. Your Change Tracking feature seems perfect for this!
To test how well this periodic checking would work, I tried it out on the Free tier. I set up a script to poll
https://api.github.com/zen every 5 minutes using fetch(..., mode="GitDiff"), since that URL gives fresh content every time....Extract Product URL's
I'm trying to extract all the product URL's from a page
eg. https://www.james-porter.co.uk/watches/all-watches OR https://watchesofknightsbridge.com
The issue is that some websites have pagination, and some don't....
How to run Extract and map results to Google Sheets using Zapier
Does anyone know of a guide for using Zapier for Extract to Google Sheets? I'm so lost, it's not documented how to set this up.
Zapier is only showing a UUID, I don't know how to map the results to Google Sheets....
externalUrls
Does anyone know definitively how the allowExternalLinks=true behaves? I was looking at the code and it seems it will only go a single page deep into an external domain, but when doing a /crawl and enabling that option, it seems like we are getting huge explosion of pages, which seems relatively unbounded.
running firecrawl and suapabase locally
Hi there. I am getting started to play with local firecrawl + local supabase and I am running into an error that seems like I have misconfigured my .env. I tried many versions and I wonder if someone can give me a hint to run firecrawl and supabase locally.
This is the error.
```
api-1 | 2025-04-15 06:48:17 error [:]: Supabase environment variables aren't configured correctly. Supabase client will not be initialized. Fix ENV configuration or disable DB authentication with USE_DB_AUTHENTICATION env variable {}...
Post scrape/crawl big datasets
Hi all, looking for suggestions on how to handle large datasets.
I am writing Jira documentation and I see AI cannot handle reading a whole page when documentation is too big, when fire crawl takes the whole page. Any good practices after I scrape with firecrawl? Like Using qdrant or pinecone but affordable? And best practices? Thanks a lot in advance....
/scrape returns null json [Activity Logs]
Hi everyone, I'm using the /scrape endpoint (llm-extract) with specific schema. My tasks are failing due to mismatch of the schema. After taking a closer look at the activity logs, even though it seems to be successful [
scrape • id: a9373d15-54ee-4b1b-9f9c-126090cfd6d1 • 6.668s • success], the JSON document I download to verify is [null] and the markdown is not downloaded (message to contact support).
Previous runs of the same scraping tasks (a few days ago) produced a valid JSON with all scraped data.
Can someone please take a look to ensure that this is not on my end?...Architecture advice
Seeking architecture advice for a real estate matching service
Hi everyone,
I'm building a real estate notification service where users enter property requirements and get alerts when matching listings appear across multiple websites and social network groups....
Scrape not sending full result.
I am using Firecrawl in a N8N workflow to scrape a site and I have encountered the issue that out of 5 results on firecrawls extract function it only seems to send the 1st to N8N. maybe not the right place to ask this but I was hoping maybe someone can give me an idea to why this is.
best way to structure a `/scrape` request
Hey everyone 👋
We’re integrating Firecrawl into our app (TOOTYA) and would love some help from the community.
We’re trying to figure out the best way to structure a
/scrape request that reliably:...Get asked to fill out onboarding everytime I try to open "dashboard"
Everytime I try to go to the dashboard I get the onboarding form.
I fill it out, it thanks me, but as soon as I navigate away or go there again I get the same thing. Same on Firefox/Chrome.
Has anyone had the same issue?...
getting company logo from crawl
hi folks, not having much success retrieving a logo url for a brand (e.g. apple.com) with the crawl endpoint
my current process is
to crawl the url via firecrawl api, and then send the html and markdown to an llm, asking the llm to find (among other things) the url of the logo (using a zod schema) from the html / markdown
...
Scraping PDFs don't work?
I am using the playground and none of the PDFs I try to scrape seems to work. Here's one: https://uinsure.co.uk/wp-content/uploads/2024/07/All-HH-IPIDs-0624.pdf
The docs mention that this is a supported use-case. Any pointers on how can I make it work?...
<head> on html content
Hey, is there a way I can get the <head> and scripts in it. I have a scenario where I want to check for any markups in there.
Not scraping all jobs
HI guys, So I've got the playground working for the following test:
https://werkenbij.forta.nl/onze-vacatures/*
It is supposed to pull all jobs, but it is only retrieving 25. Anyone any idea why it isn't pulling all 99?...
Help testing /crawl in Playground?
Hey, I'm attempting to scrape the API documentation at https://developer.fleetio.com/docs/category/api to feed to an LLM. I've been attempting to test in Playground with the /crawl method however I can only seem to extract a single page and links are not being crawled - 've tried changed Limit and Max Depth without success. Any help appreciated, thanks!
getting the apikey
Hi EveryOne, I am new to this channel. Could please let know the process to get the api key for firecrawl.