Can’t connect to pod (EU-IS-2)
Not sure if this is an issue with all regions, but trying to spin up a new pod atm (RTX 4090) and can’t connect to it via Terminal or SSH, tried refreshing page, waiting for 30 min, nothing helped
Solution:
ah looks like this is the problem lol, ill try using an earlier pytorch template
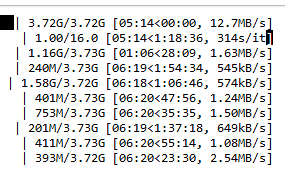
My POD is not accessible + lost access to my data
2 days ago a notice appeared next to my pod:
PLEASE CHECK ATTACHED TXT FILE FOR FULL INFO
We have detected a critical error on this machine which may affect some pods. We are looking into the root cause and apologize for any inconvenience. We would recommend backing up your data and creating a new pod in the meantime....
GPU Pod logs
Hello, i have rented a gpu pod to use it as a server for my ai models, exposed some ports and im now considering using it in a production environment,
is there a way to integrate a third party service like "Grafana" to use it for dashboarding and displaying my servers logs and status ?...
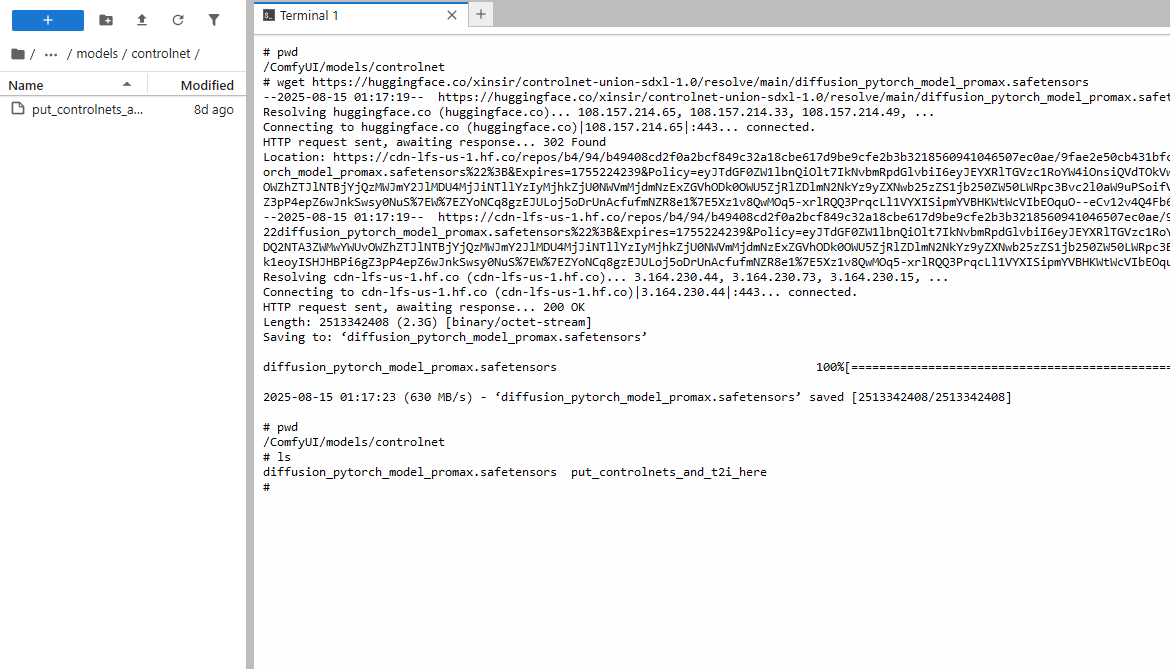
i cant use wget corrently
When I try to download a template with wget, it appears in ls but not in comfyui or in the jupterlab file browser
Disable pod restarts
Hi, I’m trying to use runpod for a large distributed fault-tolerant inference job. My containers pull from a global work queue and exit when they don’t see any work for a while. However, it seems like runpod’s default behavior is to simply restart the pod, which means I have to micromanage when to terminate my pods. Can I disable the automatic restarts and just have the pod terminate when PID 1 exits, like running a docker container normally does?
Cannot reconnect with new SSH
Hi I was SSH'd into a runpod instance but now I can't get it to connect. I've gone through the troubleshooting and did the walk through like 3 times. I also tried chatting with ai-helper and still couldn't get it.
Which images or deployment method should I use to ensure my RunPod pod is created as a v2 pod
Which images or deployment method should I use to ensure my RunPod pod is created as a v2 pod that works with the /v2/pods/{id}/exec API?
URGENT cannot download Huggingface models inside POD
In about 10 hours, I cannot download model from huggingface inside pod,
For example, getting stuck for these commands:
huggingface-cli download facebook/opt-125m
hf download facebook/opt-125m
...
Comfyui + RTX 5090 w/ Nvidia Driver 570 Issue
Most of the RTX 5090 GPUs aren't running with driver 572+, they're running with 570, and the 5090 really doesn't like that configuration for some reason (cu128+, pytorch2.7.1+, 570). Image generation workloads easily take twice as long as running on a 6000 Ada with the same docker image, and this is a somewhat known issue. While US-CA-2 has RTX 5090s with the necessary driver version (btw this is not something you can set with an image...it's entirely dictated by RunPod / the datacenter), most o...
slow speed for download lmao
Runpod is riddled with bugs. I've already submitted two complaints before. Now it's loading at a snail's pace.

runpodctl cli not installed on some containers with custom images
Is runpodctl cli meant to be installed on all images? I have been intermitantly getting the error
Error during self-termination: [Errno 2] No such file or directory: 'runpodctl'.
I am using a custom docker image...EUR-IS-1 extremely slow
From today, aug 13th, the EUR-IS-1 datacenter seems extremely slow. It was working fine yesterday.
Today, using ComfyUI with my usual template, generation times are 10x slower, and I keep getting "Disconected" messages... anyone else facing the same troubles?...
Pods disappear after removing my billings information :((
Hello there, after i removed my billings card. All my notebook and pods disappear. How do I retrieve them back :<<<< The notebook contains important stuff
Unable to determine the device handle for GPU0000:46:00.0: Unknown Error
In Scure Cloud, we started getting the following error and can't even start he pod
error creating container: nvidia-smi: exit status 255\n
---------stdout------
Unable to determine the device handle for GPU0000:46:00.0: Unknown Error...
5090 pod crashing driver issue
i got an 12.9 cuda image but the container cant start because the driver for the 5090 instance is not updated
please update all machines, at least in the US and EU...
Ram and cpu info inside pod
Hi is there any method to check cpu usage and ram usage inside a pod via the terminal. htop gives the info for the entire server instead of my pod - and it becomes very hard to identify if my process is failing due to high ram usage - can check the runod console - but it would be very helpful if I can use the pod directly for this
Setting a time limit for use
Hi. I want to know if there's a way I can set a time limit on my pod so it shuts down after, say, two hours and doesn't start up again another 12. That's one of the problems I've had is I've been using Stable Diffusion for too long. So if there's a quick way to set a time limit, let me know.
I can't figure out how to make fine tuning work
Hello everyone,
I'm seeking some expert guidance with a fine-tuning project and I'm hoping someone can help.
I have credits on this platform that I loaded specifically for fine-tuning a large language model. Unfortunately, I've had a lot of trouble getting the process to work correctly myself, and these credits are currently going unused....