Global Networking nc fails between pods in the same data center US-CA-2
i launched a H100 nvl pod, and 3 other RTX 6000 Ada pods. all on US-CA-2 and all with Global Networking on. I can nc -zv on port 22 between the GN hostnames for the RTX 6000 Ada pods, but not between the H100 and the RTX 6000 Ada (both ways), also on port 22. I've tried this with a H200 SXM as well and it does not work too. I'm supposed to be able to do so with GN (a similar set up works in US-GA-2 ).
pytorch:2.8.0-py3.11-cuda12.8.1-cudnn-devel-ubuntu22.04 container not launchable on RTX 4090 US-NC1
hi I can't launch this image on these pods on US-NC1, it seems like the cuda version loaded on them are older? is it possible to update them?
How to make cross-CUDA compatible docker?
I want to use same Docker template on different GPUs, but it turns out different GPUs have different CUDA driver and I get crashes with my venv with torch2.7.0+cu128
I wonder whats the best practice?...
"Pod Resume Failed. You can only select GPU count in multiples of 8" Error Message
I'm trying to connect to one of my running Pods that I've set up previously and haven't had any issues with. Then all of the sudden I'm getting this error message (on all my 3 running pods actually) as soon as I hit "Start for" and then select allocated GPU I get the following error message "Pod Resume Failed. You can only select GPU count in multiples of 8"
What could be wrong here? Help appreciated 🙏...

rclone S3 Connection Fails with SignatureDoesNotMatch Error (Status 403)
Description:
When attempting to list the contents of an S3 bucket (configured as sdd:) using rclone in a RunPod container environment, I encounter the following error:
```
(base) hellome@pytorch-deployment-19243627854784790530-f4765b75-llhbr:~$ rclone lsd sdd:...
Could not resolve host: github.com
Its not possible to git clone in pods ?
Solution:
For anyone dealing with similar issues:
Try adding at least a 20 second sleep in your entrypoint (untested, but it might help).
However, what definitely works 100%: put everything needed directly into the Docker image (e.g. handle git clone and similar tasks during the Docker build, not at runtime). This way, everything just works....
s3 object storage as mount
Hi im trying to mount my r2 model storage with rclone, but it fails. the same command worked locally and in google colab.
Is there a way to unlock that feature for us?...
wait times
I've been waiting on a 2 x RTX 6000 Ada Pod to start for the past 3 hours, I've been charged around 5 dollars and was wondering if this is reimbursable or if anyone has any advice on getting my money back. It's a shame because I got it working finally last night and now I've been waiting on a gpu and losing money so I might have to switch providers.
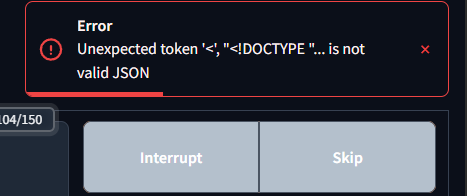
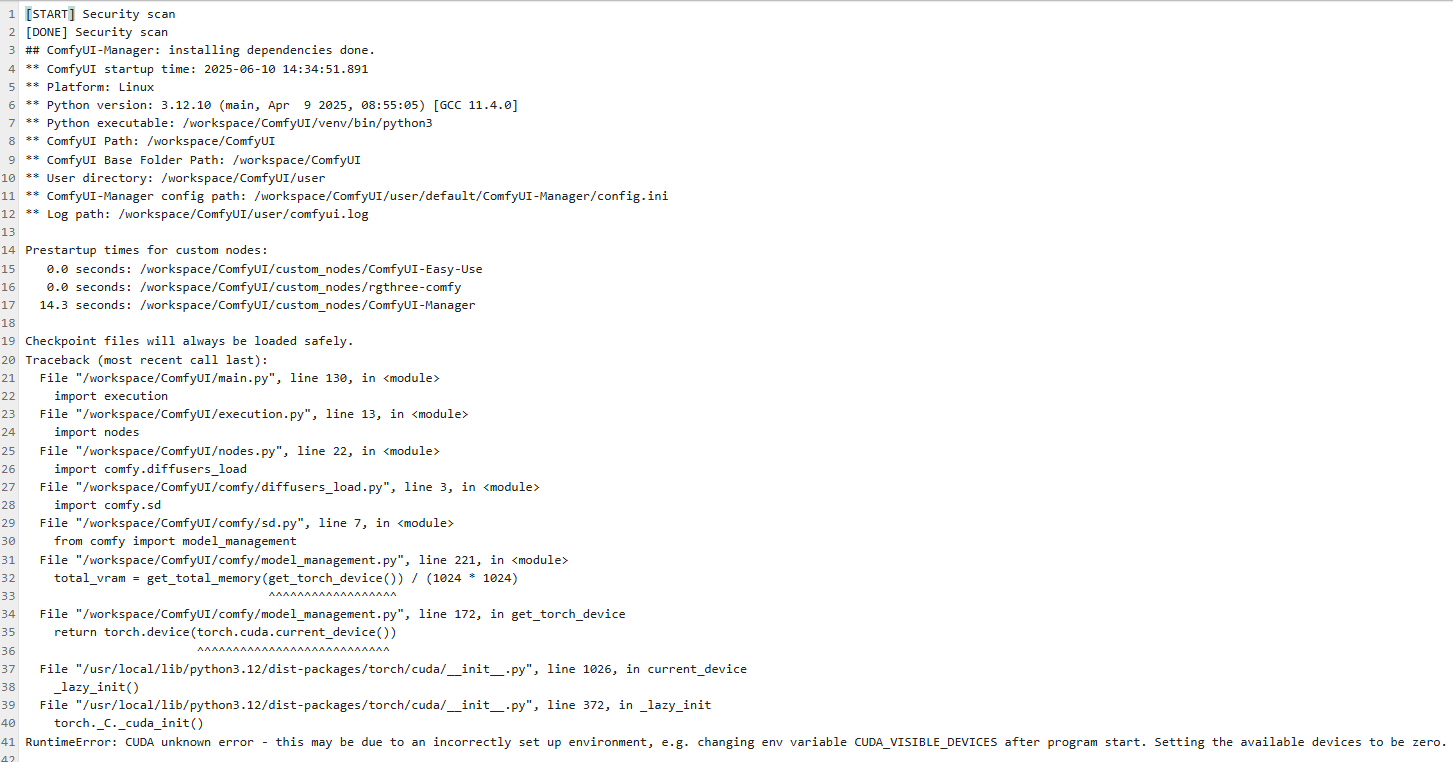
RTX PRO 6000 ComfyUI CUDA problem
Description:
Hello!
I am using a Blackwell RTX PRO 6000 GPU on a cloud server (RunPod). The GPU is correctly detected by the system (nvidia-smi works, no errors), the driver and CUDA runtime are installed. However, PyTorch cannot see any available CUDA devices and fails to initialize the GPU....
ssh
First time using runpod, is there a reason SSH wouldn't be working with an L4? The connect button was greyed out and unclickable. Or was it just that there were no available GPUs?
scp / exposed TCP ssh is not working
So. I can log in to my server through the normal ssh channel, but I can't scp via it or do other trickery to get files up there.
If I try to do the exposed TCP approach, it asks me for a password even though I have public keys set up (working for non-exposed TCP login). I've tried setting a root password in the pod, using my main account password, tried installing openssh-server in the pod, tried manually creating /etc/ssh/authorized_keys inside the pod, none of those helped, it always just denies whatever password I enter and ignores my public key.
Help? I'm about to upload lots of gigs of data to a random VPS somewhere and then download it from the pod with wget, but it's sort of ridiculous that that seems to be the only approach that works to get data up and onto the pods. Am I missing something here?...
Network disk does not save teplate
Hello, I am new to runpod and I am using the 'LoRA training - Diffusion Pipe - All In One' template. I decided to rent a Network Volume on the website, but after starting the pod all the components inside the Template are not there, just two directories. Anyone have an idea why?
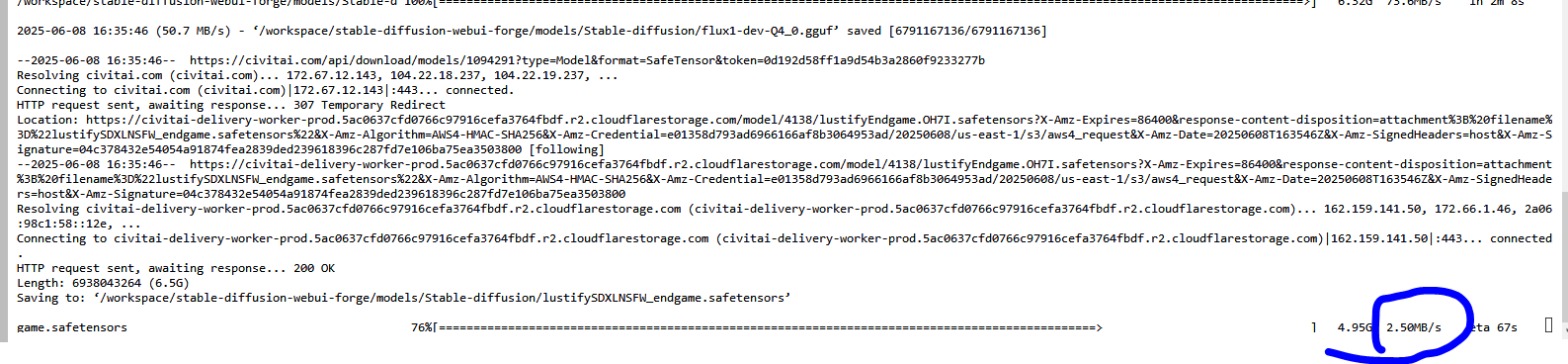
slow download
Seriously? It always has this damn problem of downloading AI models very slowly. All my money goes into downloading models, not using them...
Open Web UI not loading
I just ran a pod with
madiator2011/better-ollama-webui:cuda12.4 template.
Everything spinned up well, all ports are up and running. I'm able to hit my Ollama endpoints but for some reason the Open Web UI instance is not loading.
Stuck on this favicon placeholder image. Logs show 200 OK responses when loading the pod endpoints. I'm pretty certain the template has the OWUI_AUTH set as False....Solution:
Nevermind. It's working now, no idea why. But I'll mark as complete.

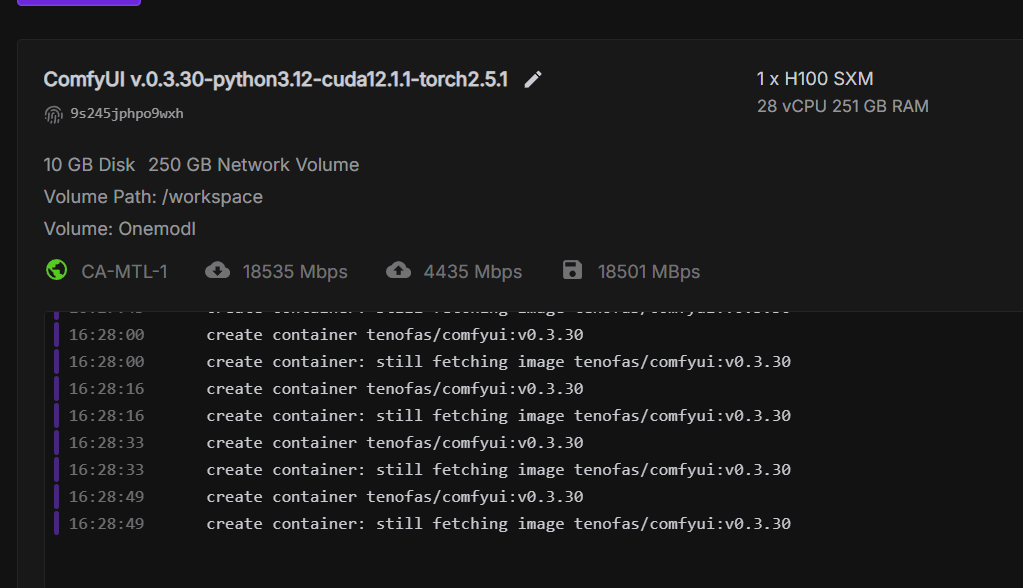
loading container image from cache
Since yesterday, and now on two different DC's, loading from cache just doesn't work.
I spent over an hour yesterday trying to load a ~4gb image from cache. A couple pods I let run for over 20 minutes before terminating. I eventually gave up on US-IL-1 where my storage was setup, and started one up on US-CA-2, which went fine as it pulled from the repo instead. I was completely loaded up, including redownloading about 30gb of models, while a pod I had left starting in IL was still "loading container image from cache."
I started up a pod on US-CA-2 at 10:08am PSD and right now it's 10:31am PSD, and still "loading container image from cache."...
Spot instance lifecycle
Hi there, is there any kind of the lifecycle notification mechanism that can help to identify that the spot instance is going to be taken away so I will be ready to move to another one?
And one more thing - is there any graceful shutdown interval / timeout for such instances?...
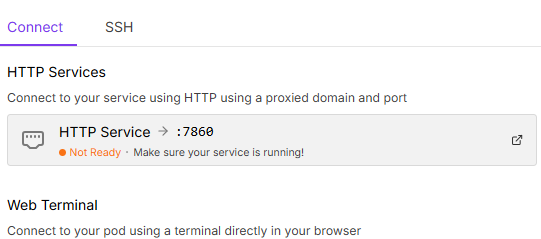
Not Ready after 45 minutes. Is this normal?
Thanks for any help. I am new to runpod and just deployed stable diffusion web-ui-10.2.1 . It shows as running, so on clicking connect, after 45 minutes is still not ready . I thinking this cant be right??
I have restarted and again waiting. Any suggestions would be really appreciated. Thanks...
Pod won't start, fetching forever
Hi, since this morning I cant start my usual workflow with ComfyUI on my pod. Any ideas?