
 F
Fi would buy RTX 4060 - 16 GB
Fmuch better
Flook for it

 K
KI can't buy anything within my budget except 3080
Fi see
Fmaybe used card?
 S
SWhat video card do you have now? I have AMD RX 6800XT 16gb and it handles Lora's training and stable diffusion quite well. The only inconvenience is that I had to install Ubuntu 20.04 on a second disk in order to have hardware acceleration
 F
Fwhat are your second / it speed per iteration speed
 J
JHey Everyone today I am recently sharing my new updated blog post please check and share your feedback.
https://jillanisofttech.medium.com/revolutionizing-llms-with-rag-navigating-the-new-frontier-in-ai-knowledge-and-trust-1b68fc3b53ec
ai
https://jillanisofttech.medium.com/revolutionizing-llms-with-rag-navigating-the-new-frontier-in-ai-knowledge-and-trust-1b68fc3b53ec
ai
Medium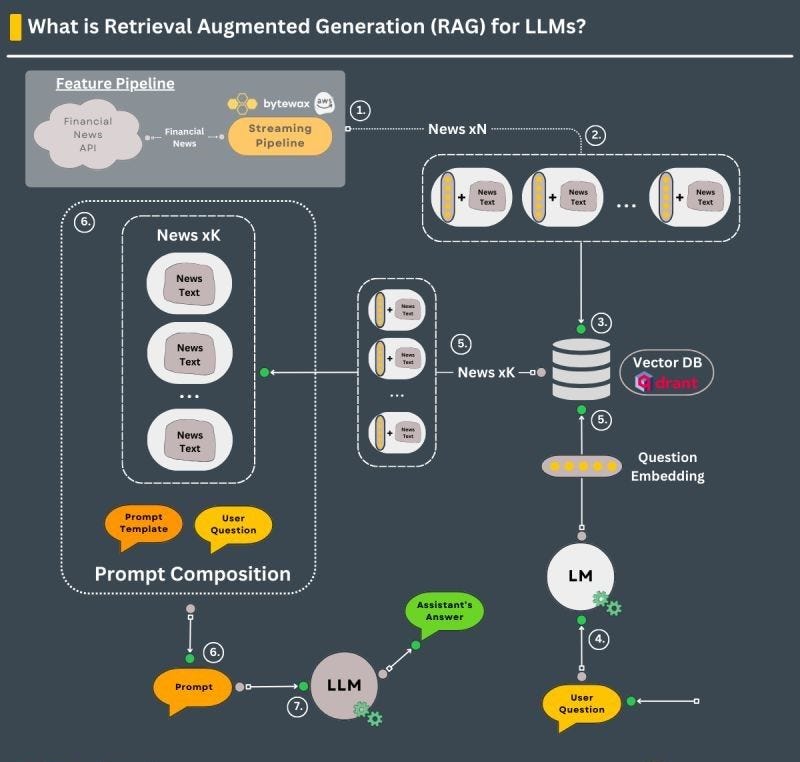
By  Muhammad Ghulam Jillani(Jillani SoftTech), Senior Data Scientist and Machine Learning Engineer
Muhammad Ghulam Jillani(Jillani SoftTech), Senior Data Scientist and Machine Learning Engineer
Muhammad Ghulam Jillani(Jillani SoftTech), Senior Data Scientist and Machine Learning EngineerKI use rx6600 and my operating system is Linux but I had to use it with docker because it was arch linux. When I installed stable diffusion directly to the system, it did not recognise the video card and worked with the processor. Somehow I managed to run stable diffusion with the video card using docker, but this time 512x512 20 step outputs took 60-90 seconds and after 4-5 outputs, the photos were distorted. Even when I tried with a proper seed and prompt, I kept getting corrupted outputs, and I was getting a 'cuda out of memory' error at the slightest setting change. I thought these speeds were normal, until I talked to someone using stable diffusion with a 3050 mobile graphics card who mentioned that he was getting outputs between 2-5 seconds. That's when I decided that I should definitely switch to NVIDIA.
Ftrue don't waste time with AMD if you are into AI
![Dazzastrous [4090]](https://cdn.discordapp.com/avatars/871389071686135838/c4a5f4d81d9eeb18d856295d692e2c07.webp?size=40) D
DPhotorealistic Video Object Insertion
MIsn't there a decent, AI, melody generator that can be used offline and the music will have a beginning and an end? Online services have a bunch, and Wondershare already gives you one for Filmora, but no such thing for offline use? The Audiocraft/MusicGen/Magnet line is forgettable, a disaster what it generates.
Fwe have auto installers for audiocraft plus
Fyou tried it?
FPatreon
Patreon is empowering a new generation of creators.
Support and engage with artists and creators as they live out their passions!
Support and engage with artists and creators as they live out their passions!
 B
BHello @Furkan Gözükara SECourses do you have notebook for deepfake on your patreon? Interested to suscribe if yes
 F
Fwe have notebook for google colab. and i have auto installer for runpod
Fwhat else you need?
BSorry I am still beginer , for what usage google colab
BBTW your vidéo are so Nice I will still sub to patron on the weekend to support ur good work
Fawesome ty so much
Fto deep fake . actually what we are doing is face transfer
Drevisiting pixart, impressive detail

![Dazzastrous [4090]](https://cdn.discordapp.com/avatars/871389071686135838/c4a5f4d81d9eeb18d856295d692e2c07.webp?size=16) F
Fyep it is great model
Fjust needed to trained with more images
JHey Everyone today I am recently sharing my new updated blog post please check and share your feedback.
https://jillanisofttech.medium.com/in-depth-data-pipeline-overview-1e8a8dece9ee
ai
https://jillanisofttech.medium.com/in-depth-data-pipeline-overview-1e8a8dece9ee
ai
Medium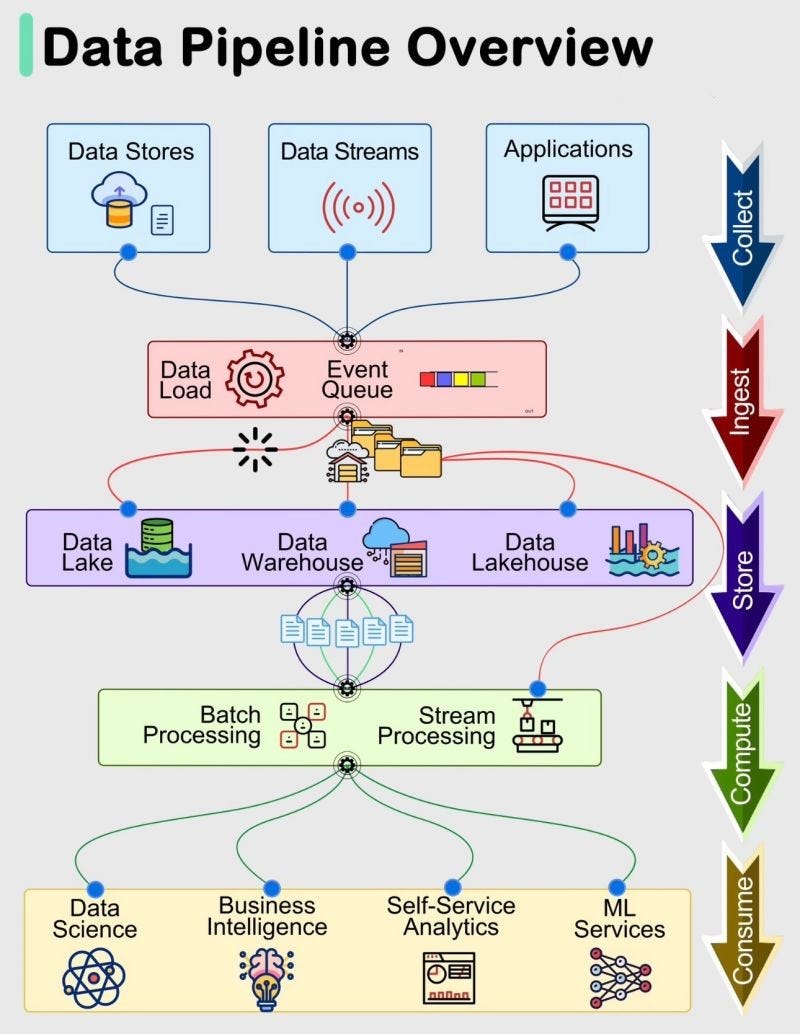
By Muhammad Ghulam Jillani(Jillani SoftTech), Senior Data Scientist and Machine Learning Engineer
Muhammad Ghulam Jillani(Jillani SoftTech), Senior Data Scientist and Machine Learning Engineer T
THey @Furkan Gözükara SECourses, I see you’re knowledgeable about LLM and image or video AI, never tried voice AI ?
 F
Fi got experience with ai voice
Ffor llm some degree
 D
D
 R
RGUYS! i need your help! does anyone know of a good site/tool/workflow that i can use to bring more detail and restore an old scanned photo?
I have my moms birthday tomorrow and this would mean the absolute world to me if someone can help me figure out a way to restore these old images to present her with for her birthday
@Furkan Gözükara SECourses (sorry for ping)
I have my moms birthday tomorrow and this would mean the absolute world to me if someone can help me figure out a way to restore these old images to present her with for her birthday
@Furkan Gözükara SECourses (sorry for ping)
 F
Fthis is also in my interest
Fbut i dont know yet
 Z
ZHello there.
I wanted to try the Ozen Toolkit: https://github.com/FurkanGozukara/ozen-toolkit.
I encountered the error below:
"Downgrade the protobuf package to 3.20.x or lower."
"Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower)."
I deleted the Conda environment and added "protobuf <= 3.20.3" to the requirements.txt. After setting it up again, it works with this change.
However, I am not sure if this is the appropriate fix as I am not a programmer. Perhaps someone more versed in Python can make a pull request with the correct fix.
I wanted to try the Ozen Toolkit: https://github.com/FurkanGozukara/ozen-toolkit.
I encountered the error below:
"Downgrade the protobuf package to 3.20.x or lower."
"Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower)."
I deleted the Conda environment and added "protobuf <= 3.20.3" to the requirements.txt. After setting it up again, it works with this change.
However, I am not sure if this is the appropriate fix as I am not a programmer. Perhaps someone more versed in Python can make a pull request with the correct fix.
ZFurthermore the whisper-large-v2 is set as default. This model could be changed to whisper-large-v3 which is the newer version
 F
Fhello. if working it is ok
Fthat is what i also usually do
 ᴏ
ᴏBeen away for sometime. What is your favorite UI for loading Text gen models? I was using oogaba, but is there anything better to load models and switch between like automatic for stable diffusion?
 F
Fi think oogaba is best one
Ffor LLMs
Fi dont know any other sadly
ᴏThank you.
 A
AHello everyone,
I want to improve myself and move to new horizons in the field of artificial intelligence, which I am passionate about. For this process, I think Generative Adversarial Networks is the field that will develop and advance me. However, when I examined it, I came across an information polluted field with hundreds of projects based on ready-made models on the internet. In this process, I would like to ask you to provide a roadmap for me to improve myself in the field of Generative Adversarial Networks and tell me how I should proceed in this process.
In this process, although I have encountered projects on creating simple Gan models, unfortunately, I have not found a resource for building our own model other than detailed ready-made models within the scope of text to image. I would be very grateful if you can suggest research resources for text to image or help me draw a road map.
I want to improve myself and move to new horizons in the field of artificial intelligence, which I am passionate about. For this process, I think Generative Adversarial Networks is the field that will develop and advance me. However, when I examined it, I came across an information polluted field with hundreds of projects based on ready-made models on the internet. In this process, I would like to ask you to provide a roadmap for me to improve myself in the field of Generative Adversarial Networks and tell me how I should proceed in this process.
In this process, although I have encountered projects on creating simple Gan models, unfortunately, I have not found a resource for building our own model other than detailed ready-made models within the scope of text to image. I would be very grateful if you can suggest research resources for text to image or help me draw a road map.
FI am interested in GANs for true deep fake training but i still didnt have time to look at that yet
FGANs are really powerful for specific purposes
AWell, do you think it makes sense to configure a ready-made model for text to image or video or to develop a model via pytorch I can develop basic Gan's models, but it is really difficult to find model examples with narration and open source in more advanced structures in this direction, do you think it would make sense to use the stabel diffuison model by customizing it?
Fi think you can try to learn how to utilize existing models
Dhttps://github.com/TencentARC/MotionCtrl this looks cool
GitHub
MotionCtrl: A Unified and Flexible Motion Controller for Video Generation - TencentARC/MotionCtrl