They are stored in the `.wrangler` directory by default
They are stored in the
.wrangler.wrangler H
H HHH
HHH P
P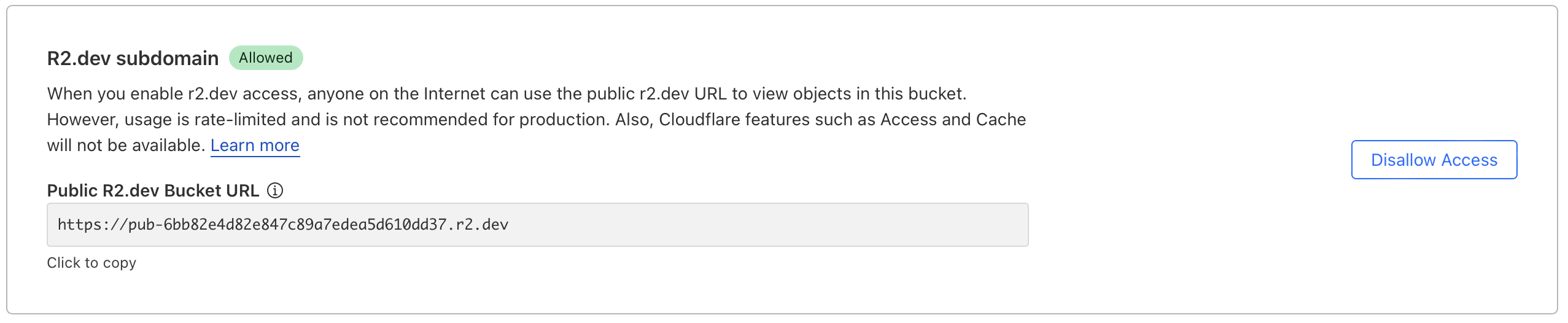
 P
P YYY
YYY IY
IY C
C C
C CC
CC IIII
IIII C
C II
II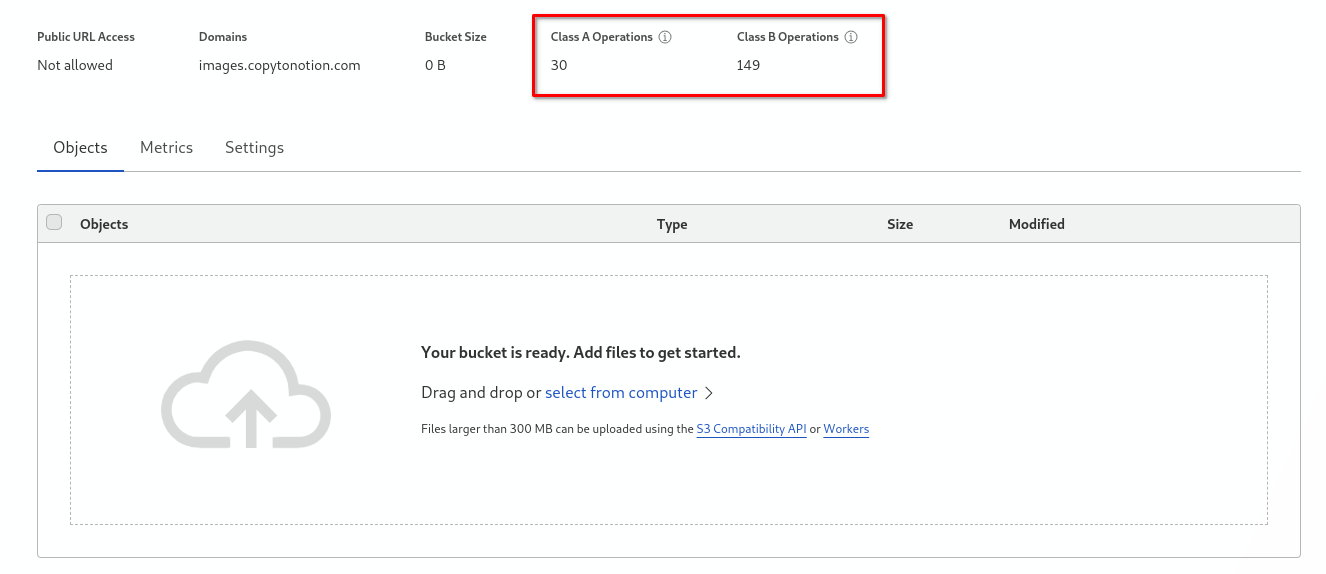
 UI
UI C
C


 KKCKCIIH
KKCKCIIH../ DCDCCDCD
DCDCCDCD JJJJ
JJJJ
 J
Jawait bucket.delete((await bucket.list()).objects.map((obj) => obj.key));






