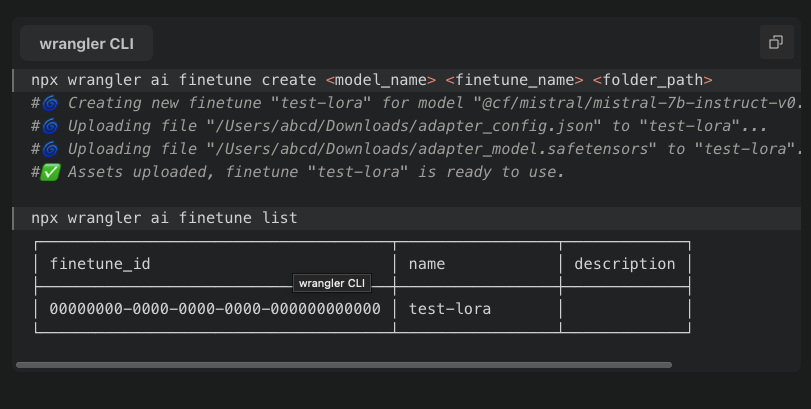
maybe something wrong with my adapters , for the record they were generated via mlx_lm , no problem Inferencing with them on my local machine via mlx_lm or Ollama.
Here my adapters_config.json
{
"adapter_file": null,
"adapter_path": "adapters",
"batch_size": 5,
"config": "lora.yml",
"data": "./data/",
"grad_checkpoint": false,
"iters": 1800,
"learning_rate": 1e-05,
"lora_layers": 19,
"lora_parameters": {
"keys": [
"self_attn.q_proj",
"self_attn.v_proj"
],
"rank": 8,
"alpha": 16.0,
"scale": 10.0,
"dropout": 0.05
},
"lr_schedule": {
"name": "cosine_decay",
"warmup": 100,
"warmup_init": 1e-07,
"arguments": [
1e-05,
1000,
1e-07
]
},
"max_seq_length": 32768,
"model": "mistralai/Mistral-7B-Instruct-v0.2",
"model_type": "mistral",
"resume_adapter_file": null,
"save_every": 100,
"seed": 0,
"steps_per_eval": 20,
"steps_per_report": 10,
"test": false,
"test_batches": 100,
"train": true,
"val_batches": -1
}{
"adapter_file": null,
"adapter_path": "adapters",
"batch_size": 5,
"config": "lora.yml",
"data": "./data/",
"grad_checkpoint": false,
"iters": 1800,
"learning_rate": 1e-05,
"lora_layers": 19,
"lora_parameters": {
"keys": [
"self_attn.q_proj",
"self_attn.v_proj"
],
"rank": 8,
"alpha": 16.0,
"scale": 10.0,
"dropout": 0.05
},
"lr_schedule": {
"name": "cosine_decay",
"warmup": 100,
"warmup_init": 1e-07,
"arguments": [
1e-05,
1000,
1e-07
]
},
"max_seq_length": 32768,
"model": "mistralai/Mistral-7B-Instruct-v0.2",
"model_type": "mistral",
"resume_adapter_file": null,
"save_every": 100,
"seed": 0,
"steps_per_eval": 20,
"steps_per_report": 10,
"test": false,
"test_batches": 100,
"train": true,
"val_batches": -1
}