Hi, I was wondering whether there is any way to improve the results of the LLAMA 3 here. I've been t
Hi, I was wondering whether there is any way to improve the results of the LLAMA 3 here. I've been trying
I am trying to classify user prompts by a list of intents. An example of prompt I am currently struggling with is "What would I need to do to learn js?". While example of intents is:
'1 Track progress and view improvements',
'2 Generate a learning plan or prepare learning materials list',
'3 Need an explanation',
'4 Seek motivation',
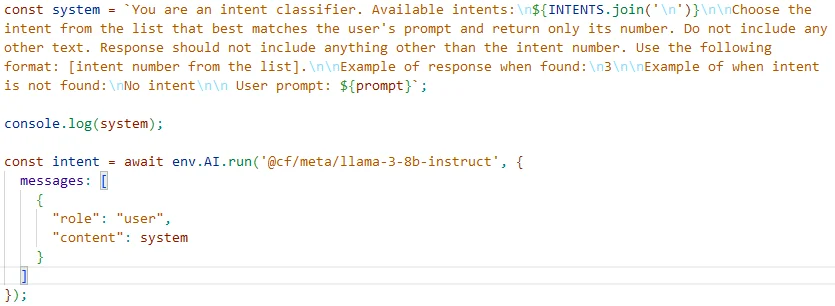
Here's how I prompt the model with the data:
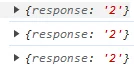
The responses to this are pretty random. I get:
1
4
3
2
3
When I moved the message from the system prompt into user prompt it started working better but the results are still really unreliable. I wanted to check with experienced people here whether my prompting is too unprecise or there is something wrong with how I understand the CF's AI.
The real issue here is that when I just use the same model on HF or Meta or even drop it into gemini or gpt-4o/3.5t all of them return perfect results, straight "2"s but not on CF
@/hf/meta-llama/meta-llama-3-8b-instruct@cf/meta/llama-3-8b-instructI am trying to classify user prompts by a list of intents. An example of prompt I am currently struggling with is "What would I need to do to learn js?". While example of intents is:
'1 Track progress and view improvements',
'2 Generate a learning plan or prepare learning materials list',
'3 Need an explanation',
'4 Seek motivation',
Here's how I prompt the model with the data:
The responses to this are pretty random. I get:
1
4
3
2
3
When I moved the message from the system prompt into user prompt it started working better but the results are still really unreliable. I wanted to check with experienced people here whether my prompting is too unprecise or there is something wrong with how I understand the CF's AI.
The real issue here is that when I just use the same model on HF or Meta or even drop it into gemini or gpt-4o/3.5t all of them return perfect results, straight "2"s but not on CF