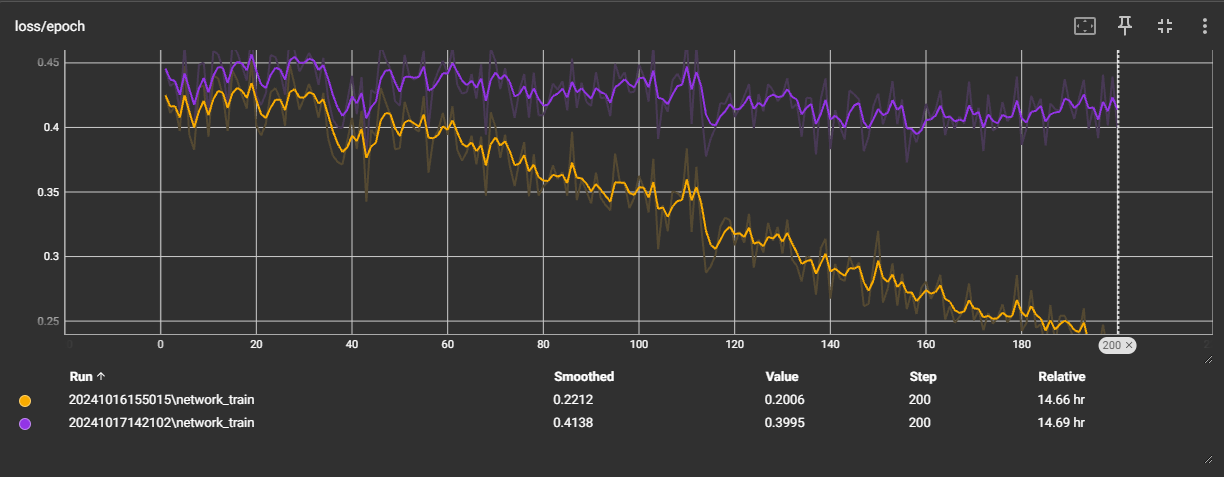
Update https://huggingface.co/nyanko7/flux-dev-de-distill training. LR 0.0001 vs 0.00003, much bette
Update https://huggingface.co/nyanko7/flux-dev-de-distill training. LR 0.0001 vs 0.00003, much better results with lower LR, may be a little undertrained. Less class bleeding, but the class on training captions seems to decrease resemblance in non de-destilled models, I think that adding the class is a problem, I will remove the class from the captions I think that it will eliminate class bleeding completely. You can always add the class on inference if you wish, but removing it from the captions will protect the class from bleeding. flux-dev-de-distill learns very different than regular flux-dev it learns the caption tokens much better. I will update tomorrow-