Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
My training on de_distill just completed (dreambooth on a single person). The ability to control cfg helps you create a far greater image than CFG 1 @ flux_dev. The results are absolutely amazing. You can create more noisier (and less plasticky images) which seem more realistic. The ability to use negative prompts and the prompt adherence is very, very good. Only downside is: Time! It sure takes helluva lot of time to generate (Minimum Steps 70 imo), and there are extra inference parameters to deal with.
Update https://huggingface.co/nyanko7/flux-dev-de-distill Lora training, removing the class did not help with class bleeding, the result was almost the same, and maybe worse because difficulted the prompting on inference. I'm doing another test with just one class and some regularization images, idk if kohya new code was implemented yet, hope this will help too.
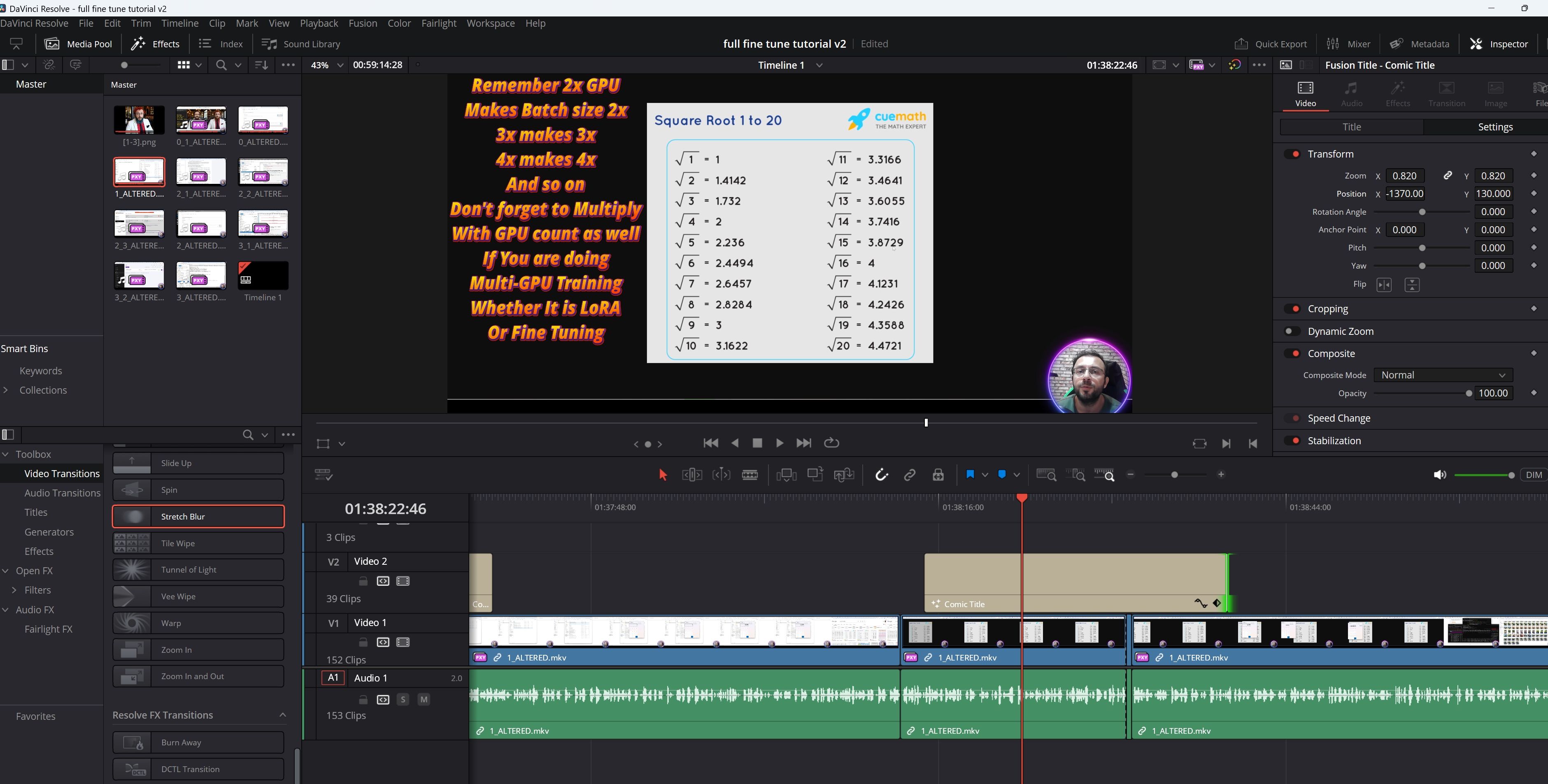
this feature is part of new webui in development, qwen-flux-wan-such This feature is part of a new webui under development, when finished, Dr. will make a tutorial on how to use it. For now I'm in the final stages and presenting some previews here. This feature only uses the image-to-image diffusion pipeline and a controlnet to refine.
 D
D D
D
 N
N F
F
 A
A W
W

 M
M
 S
S
 P
P
 A
A T
T