i am giving private consultation if you are interested in
i am giving private consultation if you are interested in
 �
�
 F
F R�RR
R�RR A
A /BillGates��RFRFFRFFRRRFR
/BillGates��RFRFFRFFRRRFR X
X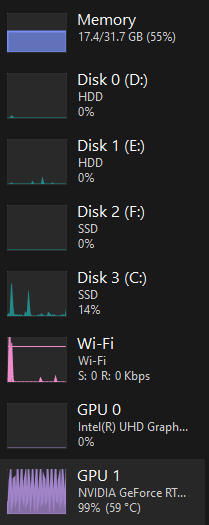 X
X--network_train_unet_only affect to the quality of the lora?XFFF ZFF�
ZFF� my current solution is inpaintinf my face with segment as shown, but face does change when using the loraFZFFZFFZZZ
my current solution is inpaintinf my face with segment as shown, but face does change when using the loraFZFFZFFZZZ
 N
N
 N
N NNN
NNN--network_train_unet_only




