Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
can you explain this, why are the eyes so bad? did sdxl lora training, 30 train pics, all great quality, many close ups on face, 150 epochs, repeat 1, 1024 resolution, biglovexl2 as base model.
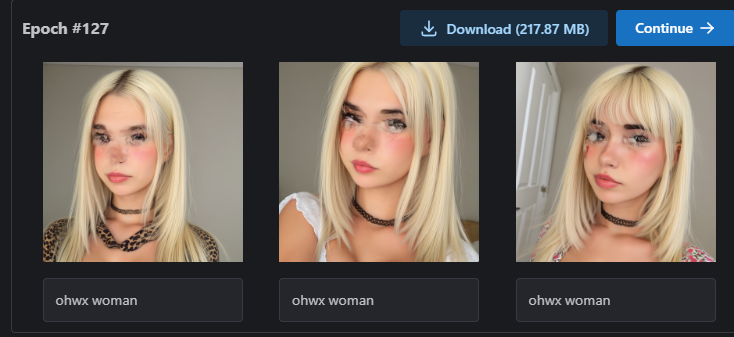
I am pleased to inform you that the dreambooth training has produced excellent results. It seems the previous difficulty arose from an incorrect learning rate. I have encountered a remaining challenge: all generated images tend to resemble the model, irrespective of the prompt utilized. Although the model was trained using the prompt "ohwx" and the class "woman," this issue persists even when the prompt is omitted or when a different subject, such as "man," is specified. Could you please offer some guidance on the potential cause of this occurrence? My objective is to generate images of other women/man in certain scenes who do not precisely replicate the trained model.
Have you had a chance to try hidream yet? I’ve been testing loras with the same data set as flux and it’s so much better. Not sure how it will cope with multiple subjects concepts but for my purpose it’s miles ahead.
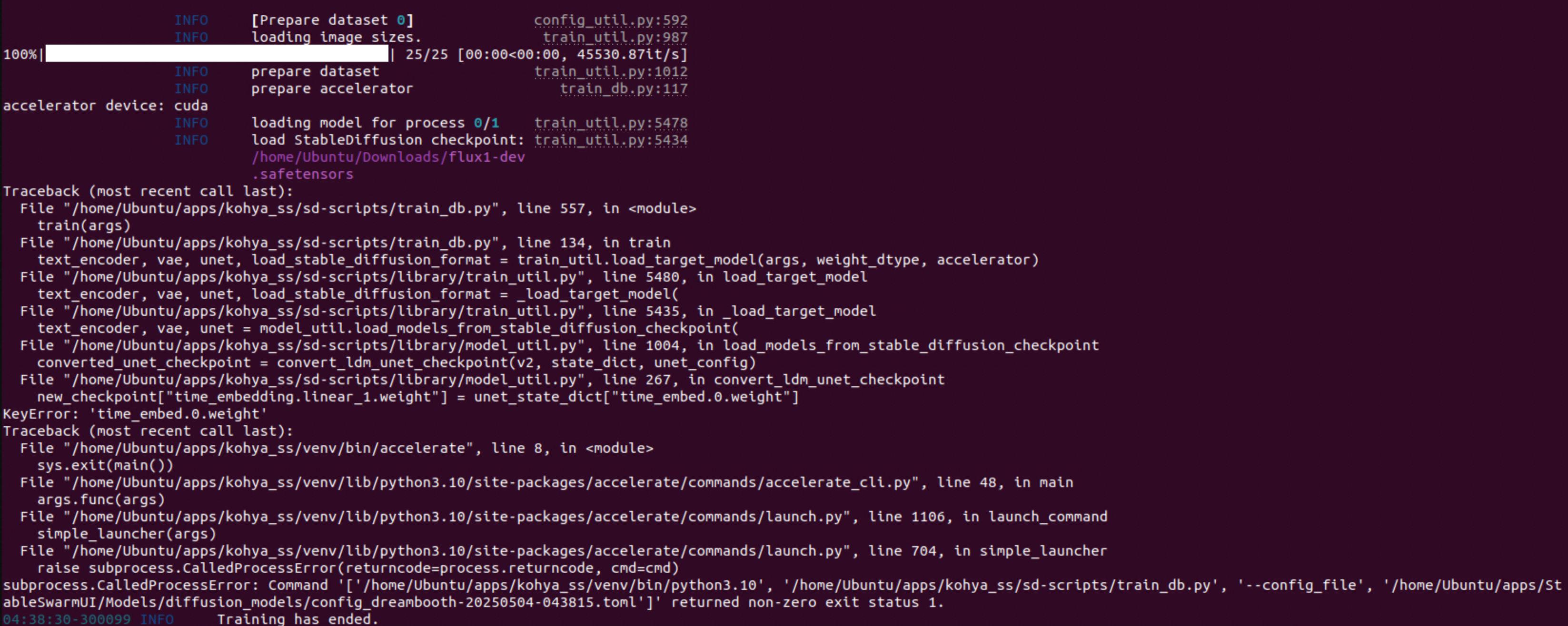
Anyone else suddenly having issues fine tuning with kohya on Massed compute? I've done this like 50 times now the past 3 months and am suddenly getting errors
Thank you Dr. And grabbing the 1024px ones will be sufficient. No point going higher. And you already cropped to make the person occupy most of the photos yes? So I don't have to run your ultimate image process on them.
doing my first sdxl fine tune with using regimages. i had 54 training images, so it looks like it's using 55 reg images per epoch, does this look right? don't wanna waste 25h
 �
�
 F
F A
A 1
1 J
J


 maybe I'll try masked training too.
maybe I'll try masked training too.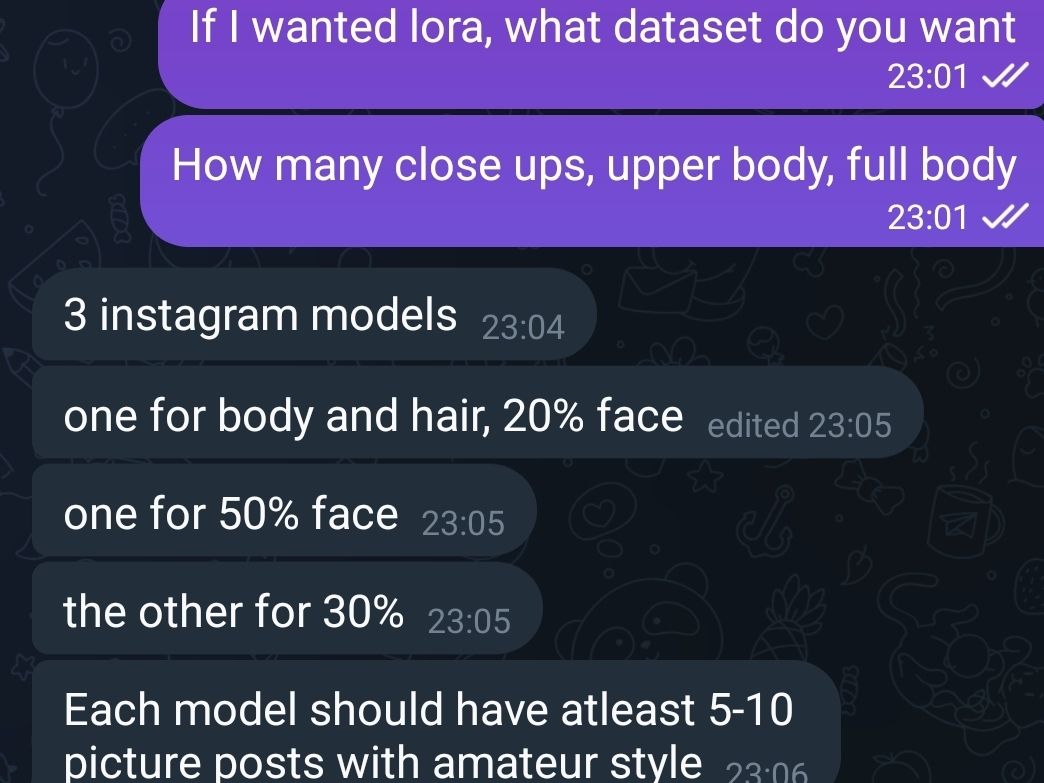
 P
P


