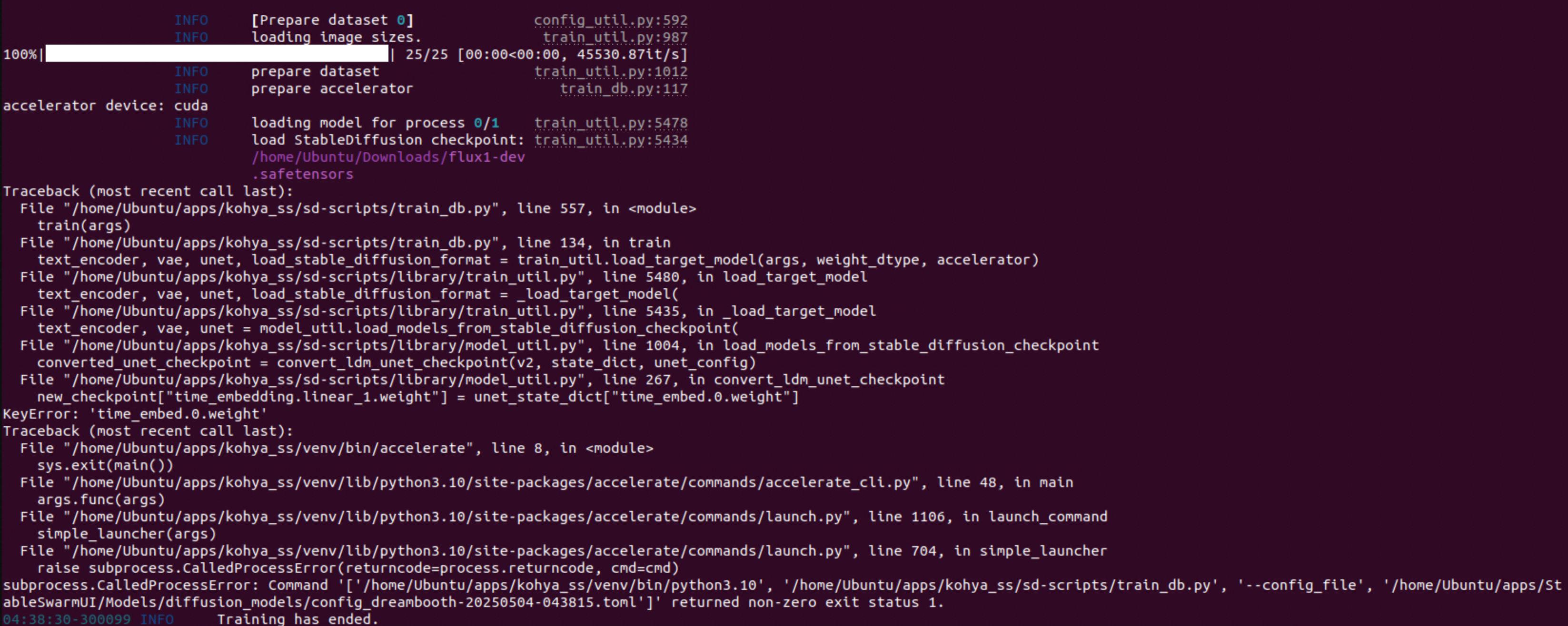
Hey Doc, how you doing today, I was just wondering if it’s possible to create a stylised flux model
Hey Doc, how you doing today, I was just wondering if it’s possible to create a stylised flux model in place of a stylised lora
 L
L FFFF
FFFF 1FFF1FFF
1FFF1FFF �
� JJ
JJ
 J��
J��
 ��FFF�
��FFF� maybe I'll try masked training too.�
maybe I'll try masked training too.�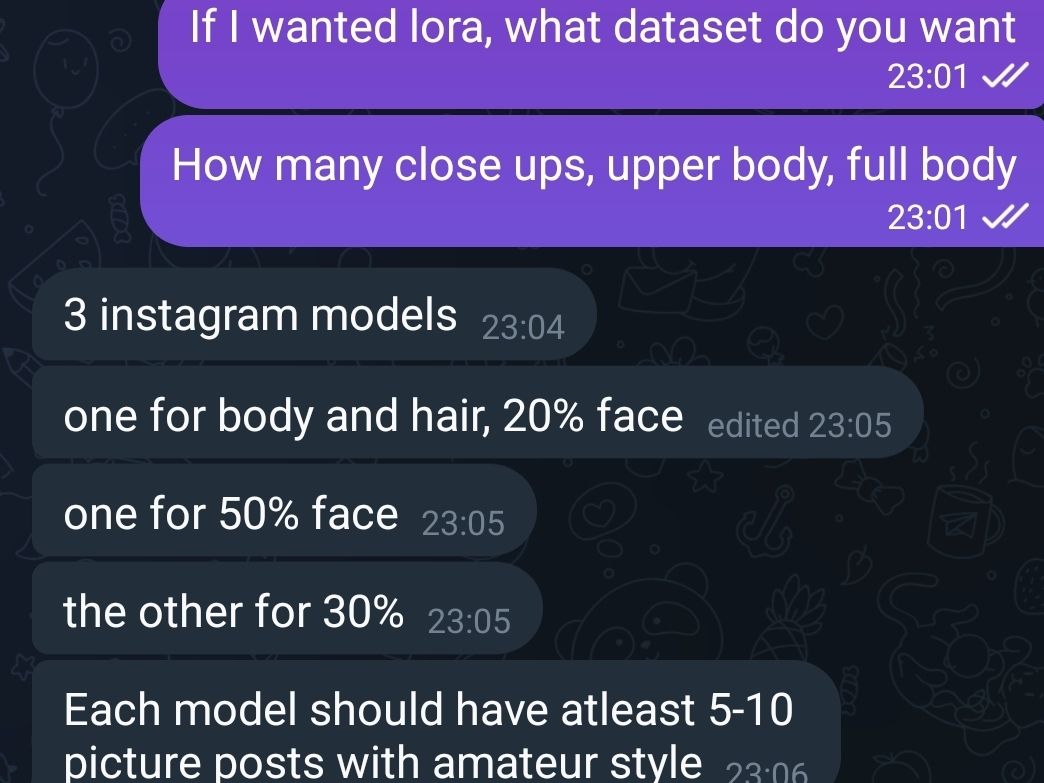
 PFFFF
PFFFF FPFFFF
FPFFFF https://www.patreon.com/SECourses
https://www.patreon.com/SECourses ��F
��F J��JJ
J��JJ S
S S
S


