workflow has very weird bugs right now, all of my instances got queue and never got released, can't
workflow has very weird bugs right now, all of my instances got queue and never got released, can't trust it right now

 A
A B
B EA
EAwrangler dev V
V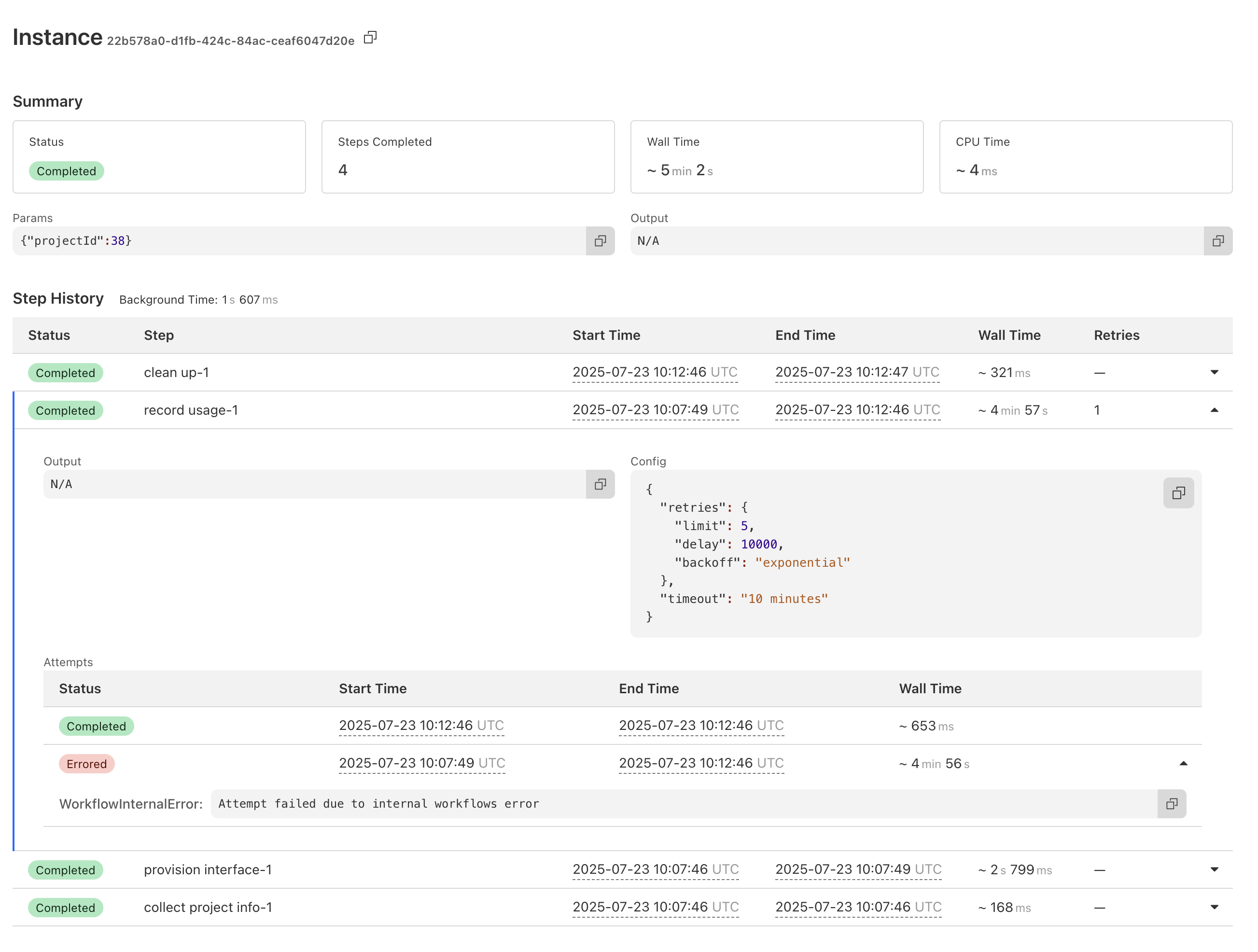 V
V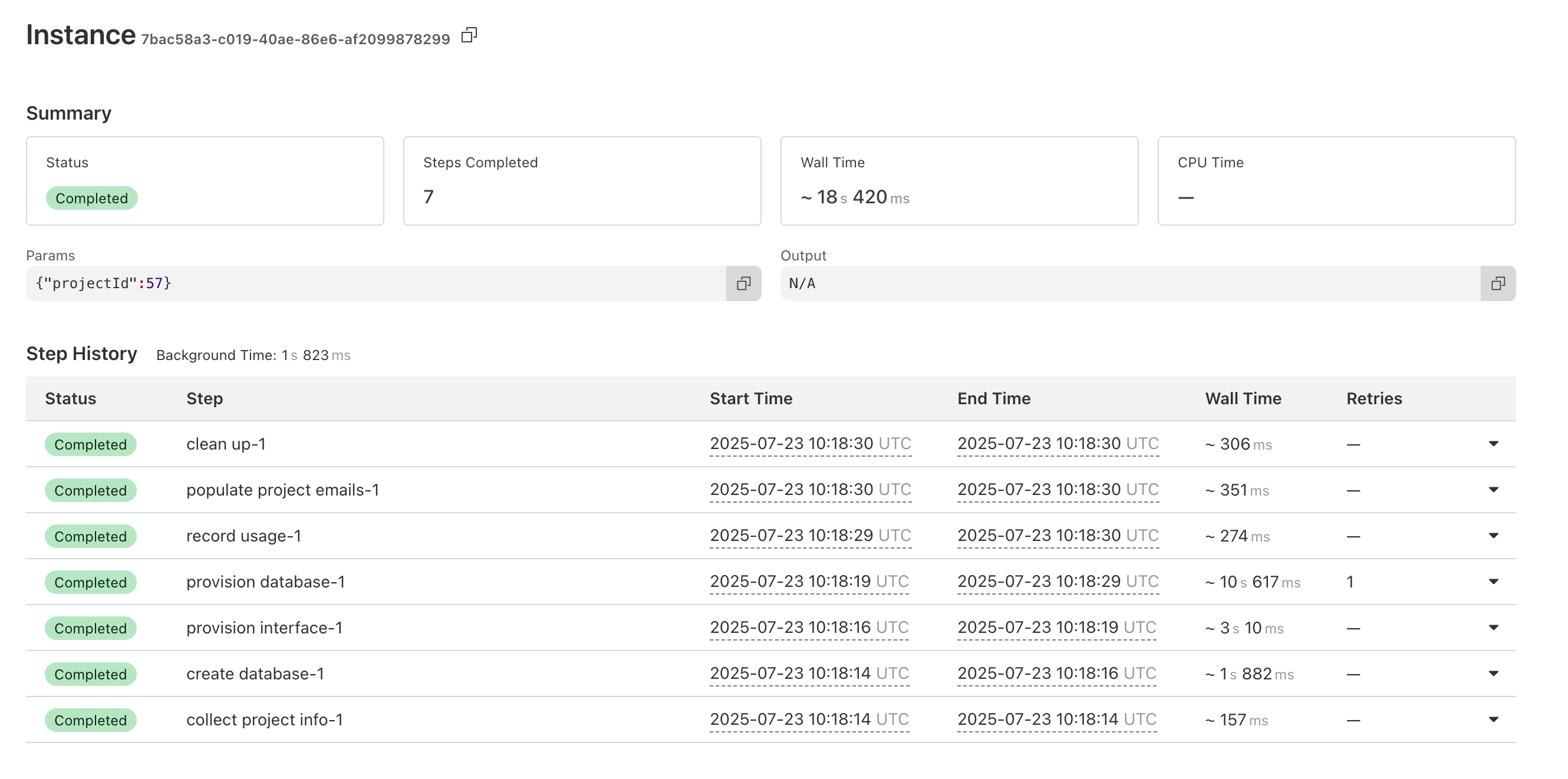 VA
VA DE
DEinvalid_id J
J D
D T
TThe RPC receiver does not implement the method "run" SS
SSApiError: {"error":{"message":"error code: 524","code":524,"status":""}} CS
CS B
B H
H DHH
DHH CC
CC A
A TC
TC
 F
F F
F
 B
B V
Vworkflows.api.error.internal_server [code: 10001]wrangler workflows ...wrangler publish K
K{ step-failed: 'blah-blah', timestamp: '' }onErrorWorkflow A
A A
AInternal Server Error
 JFB
JFB BF
BF
 D
D{retries:{limit:0}}wrangler deploytry/catch throw new NonRetryableError()Attempt failed due to internal workflows error I'm going to add a KV check to the start of the step, but am I missing something super obvious? Is there a recommended pathway for getting a step to only ever run once?J
I'm going to add a KV check to the start of the step, but am I missing something super obvious? Is there a recommended pathway for getting a step to only ever run once?J JSJM
JSJM BV
BV D
D Membership roles in "Organization Name": Contact account super admin to change your permissions.
Membership roles in "Organization Name": Contact account super admin to change your permissions. Token Permissions:V
Token Permissions:Vawait wf.complete;
console.log(await wf.output);








