im confused on the d1 free tier does it give 5gb or 1gb storage?
im confused on the d1 free tier does it give 5gb or 1gb storage?

 L
L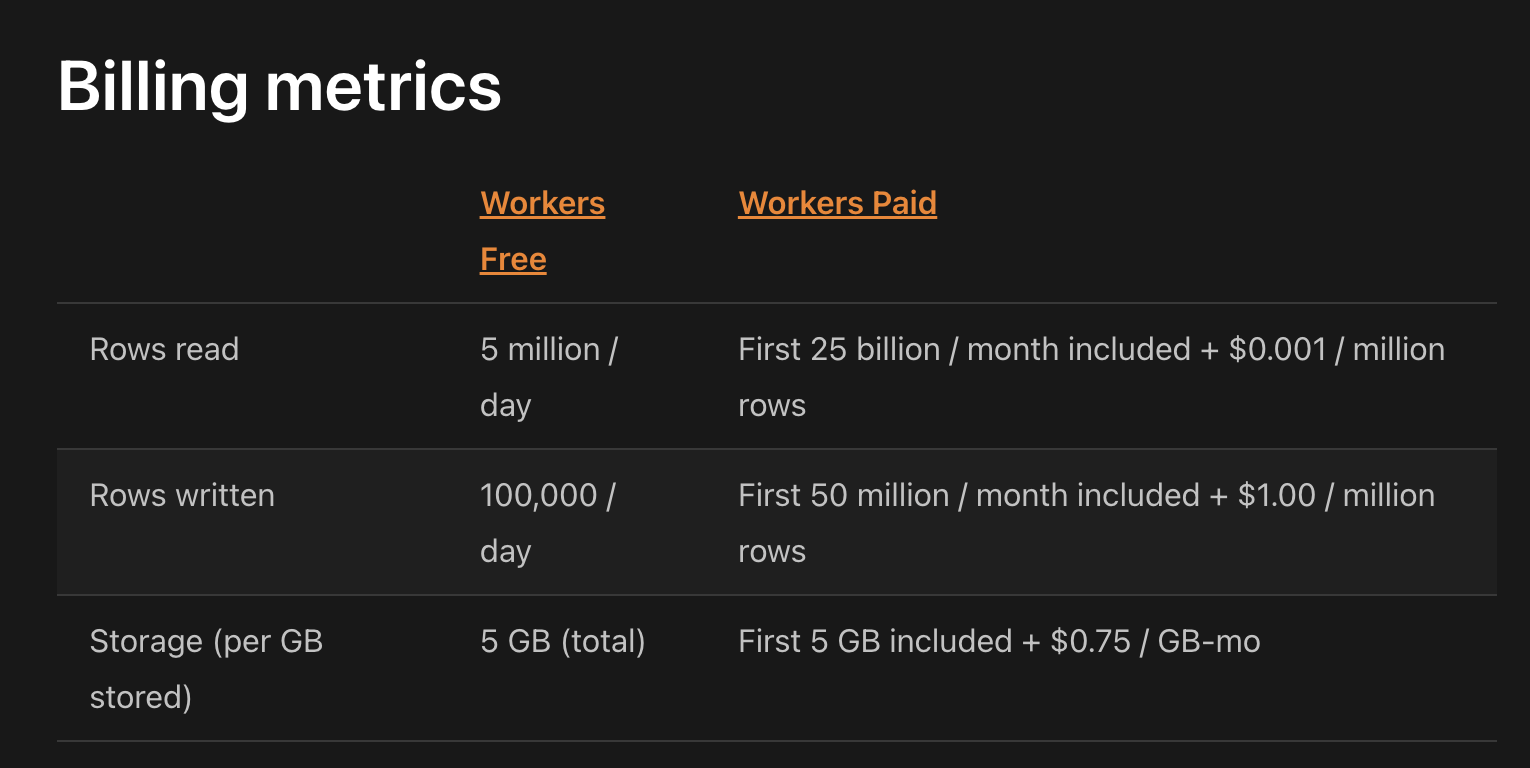
 D
D LLLLLLLLLLL
LLLLLLLLLLL NLNL
NLNL MMMMMMM
MMMMMMM AL
AL OJ
OJ M
M
 G
G SL
SLbind() J
J
 TT
TT GLL
GLL LGMG
LGMG ADL
ADL D
D├── packages/
│ ├── worker/
│ └── db/
└── apps/
└── app1/
└── app2/![[A]nToNin](https://cdn.discordapp.com/avatars/190059732608745472/b687f88d485d8366da6ac2c695d624bb.webp?size=16)











