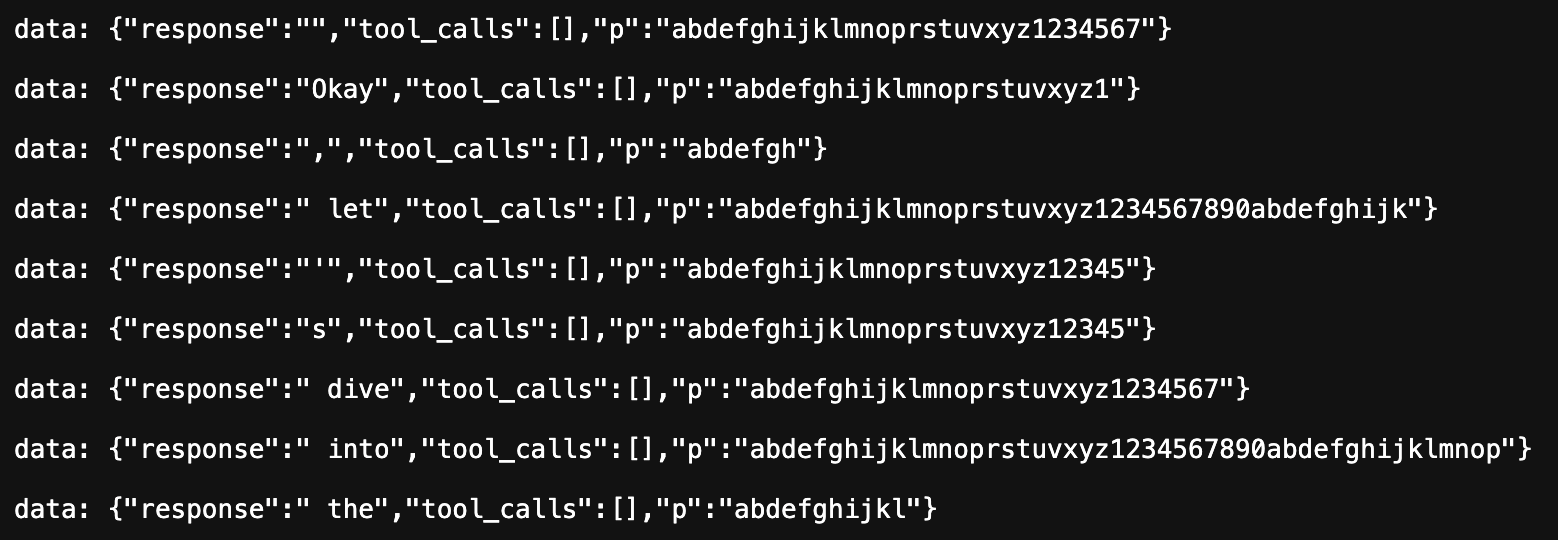
Hey @Sudhan . There are a couple of things that might help here: 1. you can pass in a stream of by
Hey @Sudhan . There are a couple of things that might help here:
1. you can pass in a stream of bytes for the inputs in many of the models, e.g. in the nova-3 example you can fetch and pass in the body directly (without needing to await it: https://developers.cloudflare.com/workers-ai/models/nova-3/)
2. Some models (like nova-3) support our async batch API (https://developers.cloudflare.com/workers-ai/features/batch-api/). So you can submit the job for running the inference and then poll for the response.
In both cases, it shouldn't be using much compute in the worker itself.
1. you can pass in a stream of bytes for the inputs in many of the models, e.g. in the nova-3 example you can fetch and pass in the body directly (without needing to await it: https://developers.cloudflare.com/workers-ai/models/nova-3/)
2. Some models (like nova-3) support our async batch API (https://developers.cloudflare.com/workers-ai/features/batch-api/). So you can submit the job for running the inference and then poll for the response.
In both cases, it shouldn't be using much compute in the worker itself.