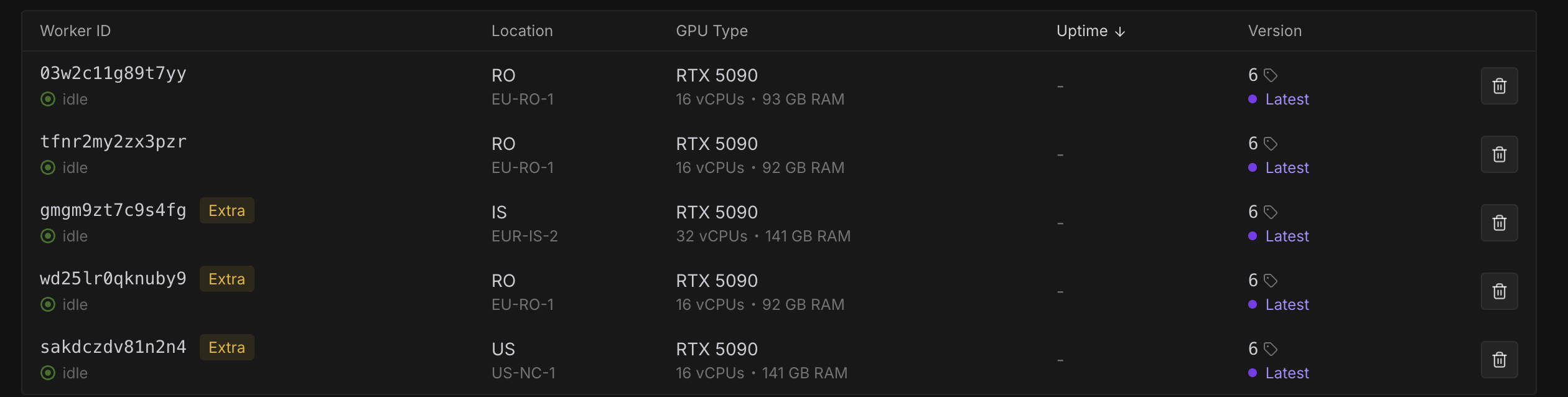
value not in list on serverless
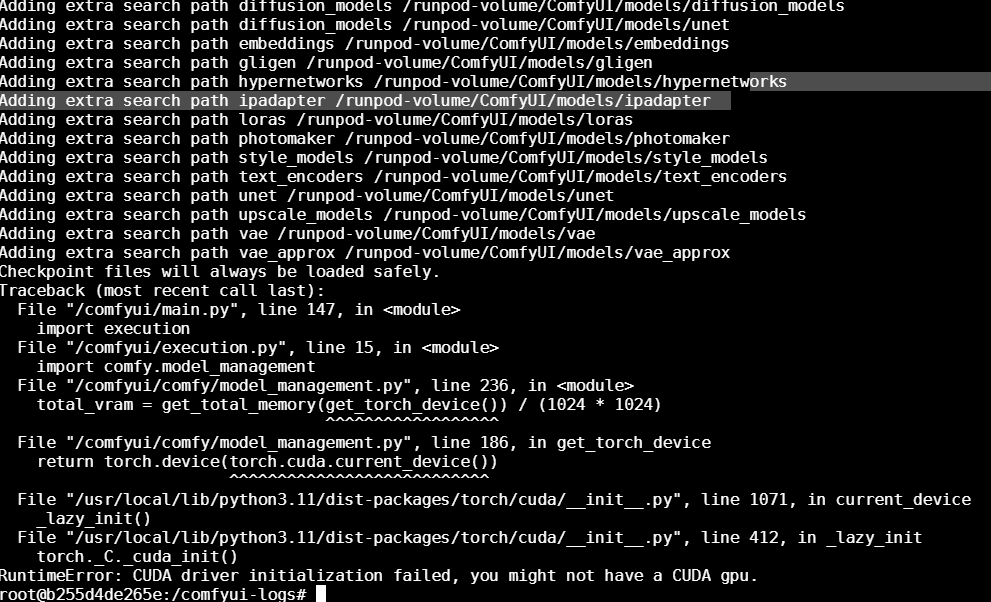
Finish task with error: CUDA error: no kernel image is available for execution on the device
Runpod underwater?
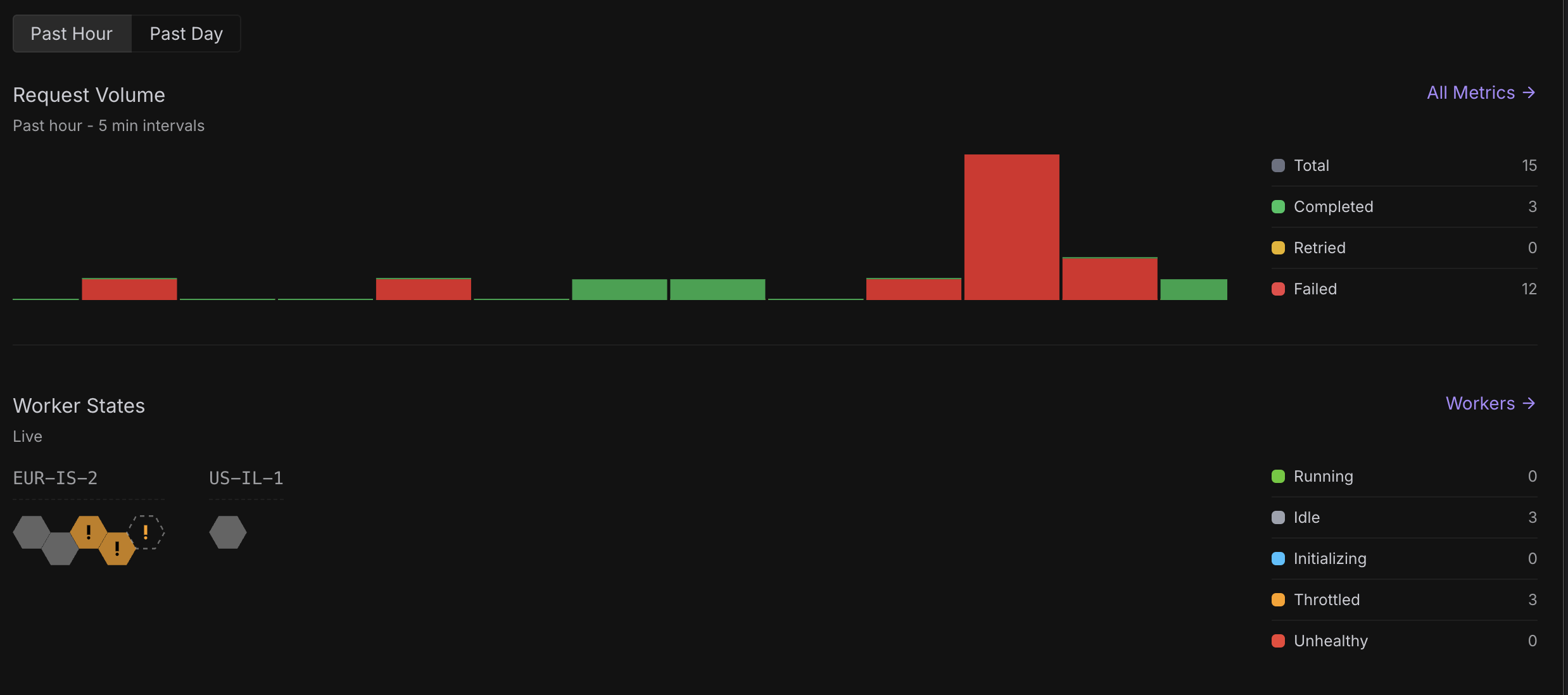
Failing requests
A deposit error caused me to lose money, any Runpod staff providing support?
So whats the deal with all the issues and the charging for failed docker fetches?
Having trouble using ModelPatchLoader in Comfyui Serverless
{'delayTime': 618, 'error': 'Workflow validation failed:\n• Node 39 (errors): [{\'type\': \'value_not_in_list\', \'message\': \'Value not in list\', \'details\': "name: \'uso-flux1-projector-v1.safetensors\' not in []", \'extra_info\': {\'input_name\': \'name\', \'input_config\': [[], {}], \'received_value\': \'uso-flux1-projector-v1.safetensors\'}}]\n• Node 39 (dependent_outputs): [\'9\']\n• Node 39 (class_type): ModelPatchLoader', 'executionTime': 323, 'id': 'sync-445ef416-ddcf-4a2c-bba7-fd6bc9e192a3-u1', 'status': 'FAILED', 'workerId': 'aehi12zofrz99h'}
I'm wondering if anyone has any insights into this?...I have some questions about Serverless scaling and account limits
workersMax limit for Serverless endpoints?
2. Is there an overall account-level quota that limits total concurrent workers across all endpoints?
3. If so, is it possible to request a higher limit for production workloads?...GPU Detection Failure Across 20–50% of Workers — Months of Unresolved Issues
Question about Serverless max workers, account quota limits, and using multiple accounts
workersMax limit for Serverless endpoints?...How to use Python package for public endpoints?
What are some good analogues of Runpod Serverless?
Finish task with error: CUDA error: no kernel image is available for execution on the device
3czrvanpdpzxz3[error] [31m[2025-10-14 19:48:25] ERROR [0m [34m[Task Queue] Finish task with error: CUDA error: no kernel image is available for execution on the device\n
3czrvanpdpzxz3[error] [31m[2025-10-14 19:48:25] ERROR [0m [34m[Task Queue] Finish task with error: CUDA error: no kernel image is available for execution on the device\n
Throttling on multiple endpoints and failed workers
Ongoing Throttling Issues with Multiple Serverless Endpoints
Serverless throttled
Huggingface cached models seems to not working
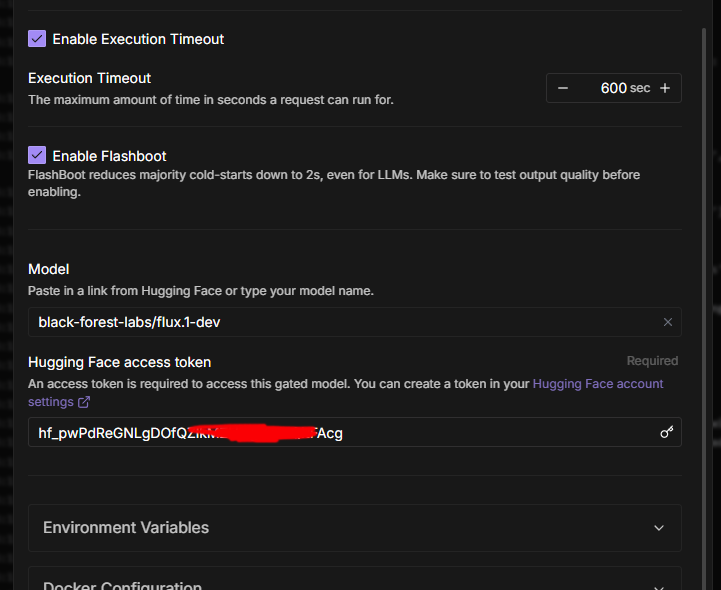
vLLM jobs not processing: "deferring container creation"