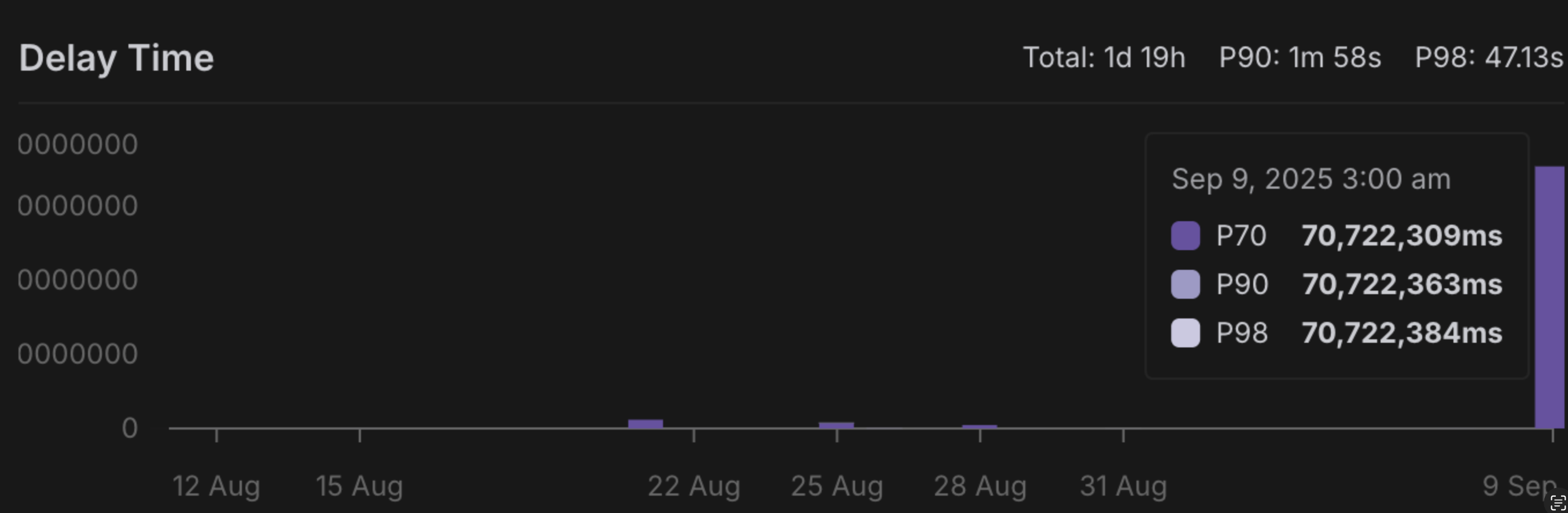
Extremely High Delay Time
Serverless endpoint deployment: Something went wrong. Please try again later or contact support.
How long is the delay on serverless?

File caching question
Help! I want to use the public enpoint. Crazy hallucination with the standard format
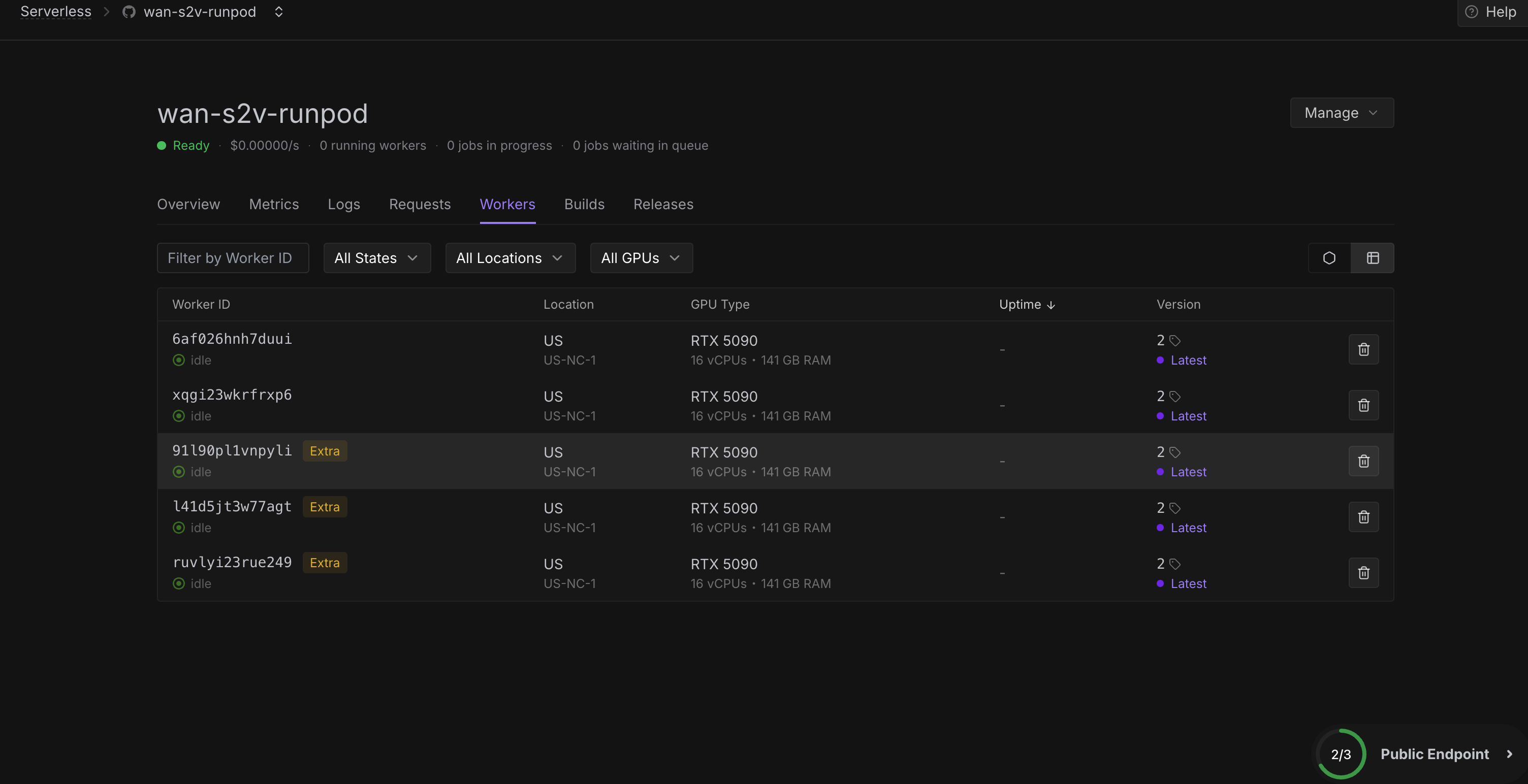
Workers stuck at "Running" indefinitely until removed by hand

Workers are getting throttled
Serverless shared workers?
build stuck at pending before it starts building
Intermittent "CUDA error: device-side assert triggered" on Runpod Serverless GPU Worker
Typescript handler functions
Not receiving webhook requests after job finishes
am i billed for any of this
Unauthorized while pulling image for Faster Whisper Template from Hub
ComfyUI Serverless Worker CUDA Errors
CUDA error comfyui
Workflow execution error: Node Type: CLIPTextEncode, Node ID: 10, Message: CUDA error: no kernel image is available for execution on the device\nCUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.\nFor debugging consider passing CUDA_LAUNCH_BLOCKING=1\nCompile with TORCH_USE_CUDA_DSA to enable device-side assertions.\n\n"...Is there any way to force stop a worker?
Long delay time