just got word that sd3 8b will be out soon, no distilation and easier to train and finetune
just got word that sd3 8b will be out soon, no distilation and easier to train and finetune
 MMM
MMM FM
FM9/14/24, 11:30 AM
F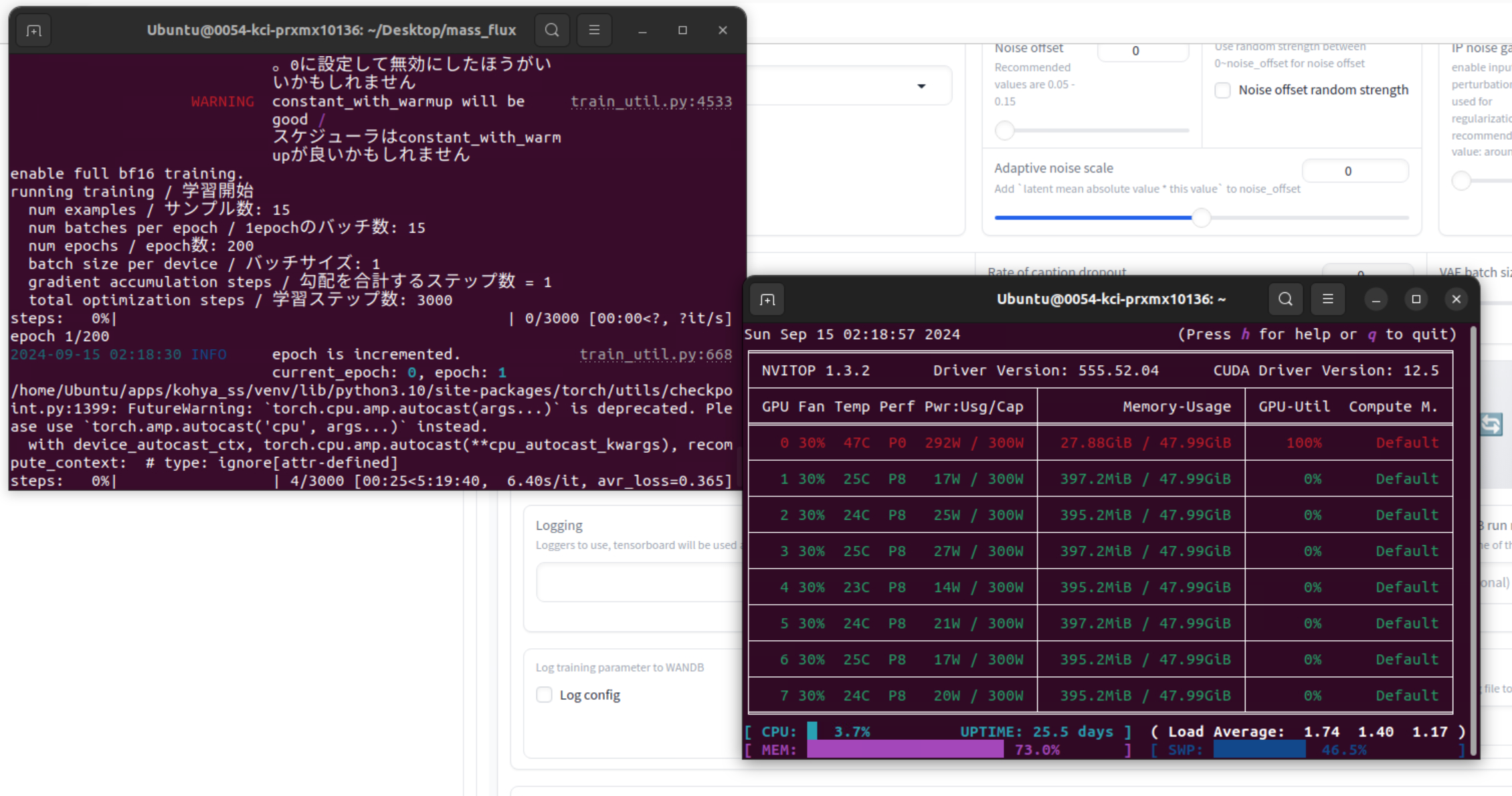 FFFMFFFFFFMFFMFFF
FFFMFFFFFFMFFMFFF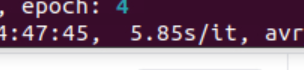 MFF
MFF MFFF
MFFF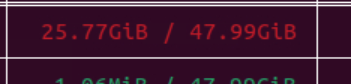 M
M DD
DD F
F FFFFF
FFFFF F
F![Dazzastrous [4090]](https://cdn.discordapp.com/avatars/871389071686135838/c4a5f4d81d9eeb18d856295d692e2c07.webp?size=40) DFFF
DFFF A
A
 A
A DF
DF V
V

