Keep in mind visits != D1 queries but still, D1 can easily handle it, yes 😄
Keep in mind visits != D1 queries but still, D1 can easily handle it, yes 

 AA
AA �
� S
S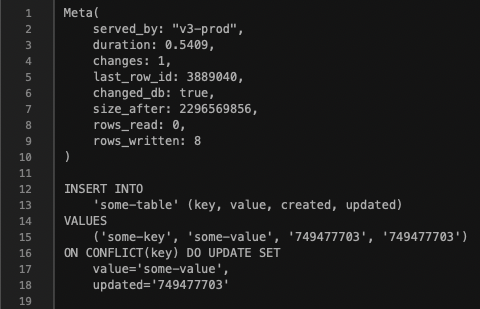
 SSSS
SSSS L
LbatchBatched statements are SQL transactions. If a statement in the sequence fails, then an error is returned for that specific statement, and it aborts or rolls back the entire sequence.
 LSL
LSLgoogleUser.emailbatch()nanoid().get().then((res) => res?.id!) JJ
JJ O
O �L��
�L�� DL
DL.wrangler If things break, you can clean up and reset by deleting those files.D
If things break, you can clean up and reset by deleting those files.D D
D199187a5c9948d6a9eaef3ee19490fb5eec30c2012c4b4101aaeb362f07f1d3e.sqlite C
Cwrangler d1 execute —local <query> DDDDMMMM
DDDDMMMM B
B ZMM
ZMM D
D K
K
 L
Lsql.exec()sharedDB.batch([
sharedDB.insert(usersTable).values({
publicId: nanoid(),
name: googleUser.name,
email: googleUser.email
}).onConflictDoNothing()
.returning(),
sharedDB.insert(oauthAccountsTable).values({
providerId: "google",
providerUserId: googleUser.sub,
userId:// !!! no id
})
])await sharedDB.batch([
sharedDB.insert(usersTable).values({
publicId: nanoid(),
name: googleUser.name,
email: googleUser.email
}).onConflictDoNothing()
.returning(),
sharedDB.insert(oauthAccountsTable).values({
providerId: "google",
providerUserId: googleUser.sub,
userId: await sharedDB.select({ id: usersTable.id }).from(usersTable).where(eq(usersTable.email, googleUser.email)).get().then((res) => res?.id!),
})
])







