
Welcome to the official Cloudflare Developers server. Here you can ask for help and stay updated with the latest news
83,498Members
View on DiscordResources
Similar Threads
Was this page helpful?
 S
S S
S L
Lbatch call are executed inside a single transaction: https://developers.cloudflare.com/d1/build-with-d1/d1-client-api/#batch-statementsBatched statements are SQL transactions. If a statement in the sequence fails, then an error is returned for that specific statement, and it aborts or rolls back the entire sequence.
 LSL
LSLgoogleUser.email and use that in your INSERT. ���L
���Lbatch(), but your second INSERT should do a nested SELECT to figure out the user ID that was added in the first insert.nanoid() into a local variable before you create your statements, and use that in both queries. Isn't that nanoid what you want in the second insert or is it an autoincrement key?���L.get().then((res) => res?.id!) part needs the query to actually run I imagine. I am not familiar with this framework you are using for constructing your queries. JJ
JJ O
O �L��
�L�� DL
DL.wrangler, but don't mess them up outside of your worker code to avoid unexpected behavior  If things break, you can clean up and reset by deleting those files.D
If things break, you can clean up and reset by deleting those files.D D
D199187a5c9948d6a9eaef3ee19490fb5eec30c2012c4b4101aaeb362f07f1d3e.sqliteD C
Cwrangler d1 execute —local <query> https://developers.cloudflare.com/workers/wrangler/commands/#execute DDDDMMMM
DDDDMMMM B
B ZMM
ZMM D
D K
K
 L
Lsql.exec() interface. AA
AA
 D
Dwrangler pages deploy --branch $BITBUCKET_BRANCH to deploy a preview environment and wrangler d1 migrations apply --remote --env preview to apply the migrations to the preview db. that's awesome and pretty easy. however, all the preview envs share the same database, so how should I handle two PRs making db changes? or another very common use case: I start my PR with a single db change, but after PR reviews, I want to add/remove changes from the migration.rm -rf ./.wrangler/state/v3/d1 and re-apply the migrations from main. A
A P
P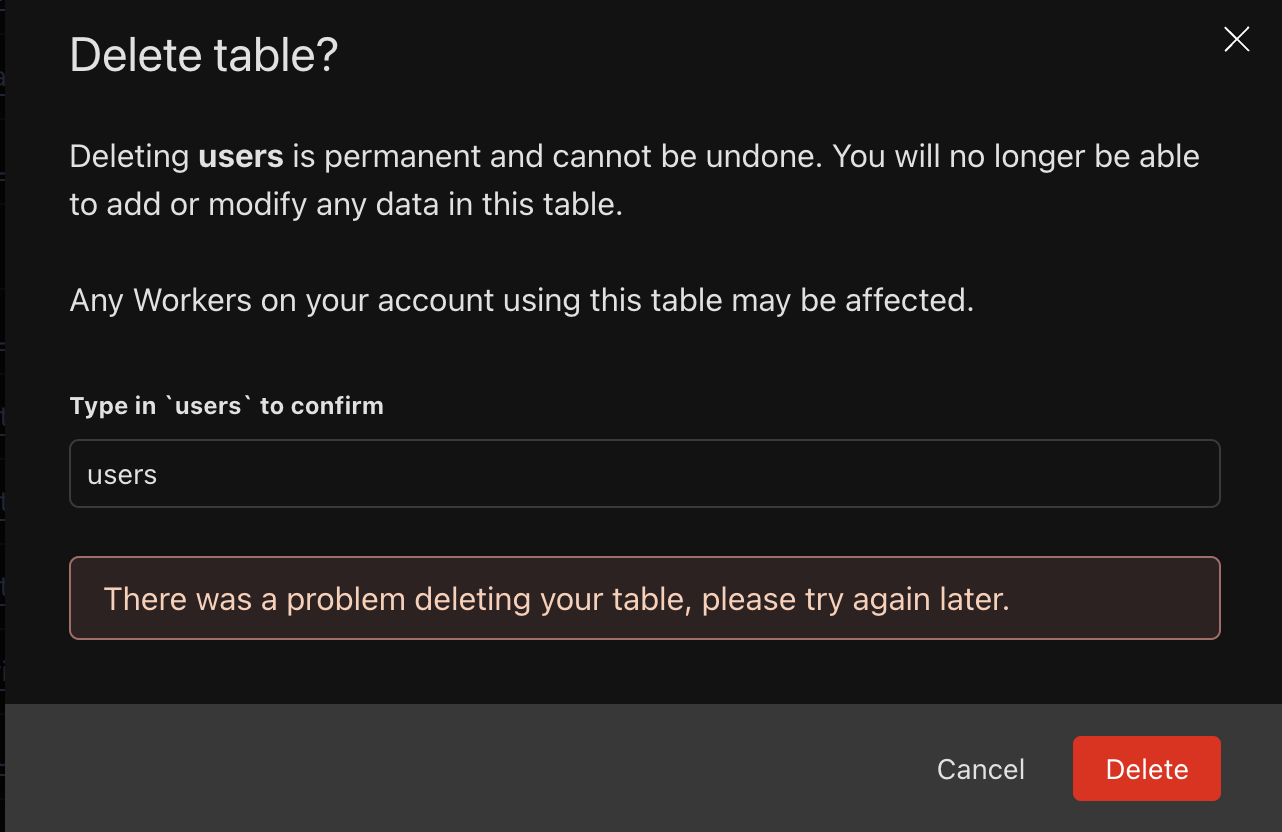 P
P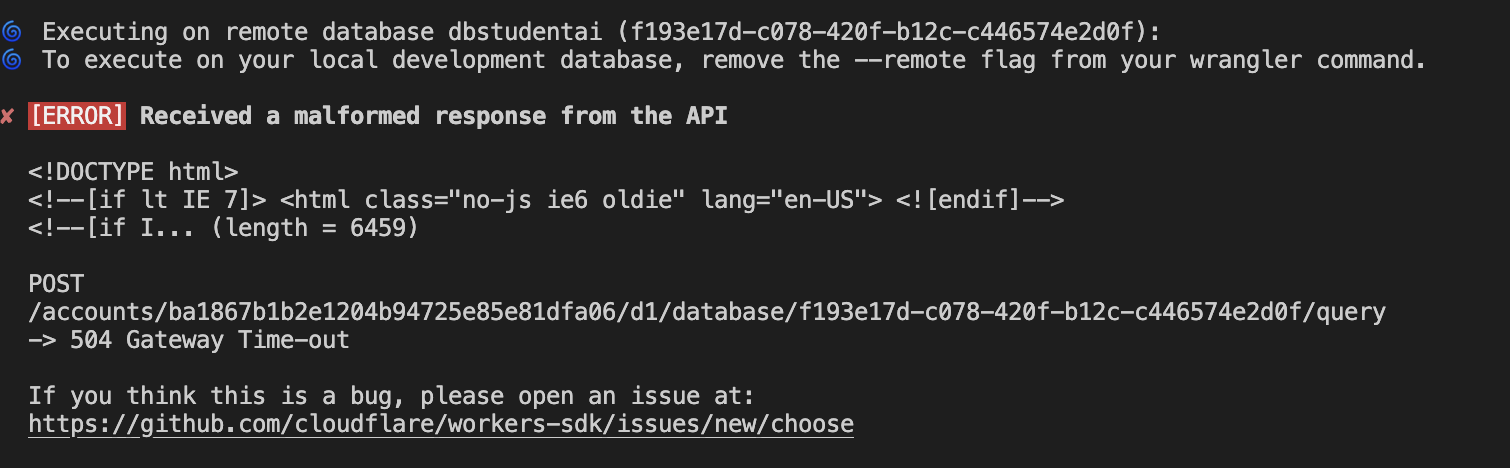 P
Pbatchnpx prisma migrate diff --from-url ????here remote d1 --to-schema-datamodel ./prisma/schema.prisma --script --output migrations/0002_second.sqlgoogleUser.emailbatch()nanoid()await sharedDB.batch([
sharedDB.insert(usersTable).values({
publicId: nanoid(),
name: googleUser.name,
email: googleUser.email
}).onConflictDoNothing()
.returning(),
sharedDB.insert(oauthAccountsTable).values({
providerId: "google",
providerUserId: googleUser.sub,
userId: await sharedDB.select({ id: usersTable.id }).from(usersTable).where(eq(usersTable.email, googleUser.email)).get().then((res) => res?.id!),
})
]).get().then((res) => res?.id!).wrangler199187a5c9948d6a9eaef3ee19490fb5eec30c2012c4b4101aaeb362f07f1d3e.sqlitewrangler d1 execute —local <query>sql.exec()wrangler pages deploy --branch $BITBUCKET_BRANCHwrangler d1 migrations apply --remote --env previewrm -rf ./.wrangler/state/v3/d1main








