Oh, I think I have run into this actually.. does this translate to about 60 concurrent Workers then?
Oh, I think I have run into this actually.. does this translate to about 60 concurrent Workers then? Or more?
 AAAA
AAAA S
S{ connect_timeout: 1, max: 5 }setTimeout(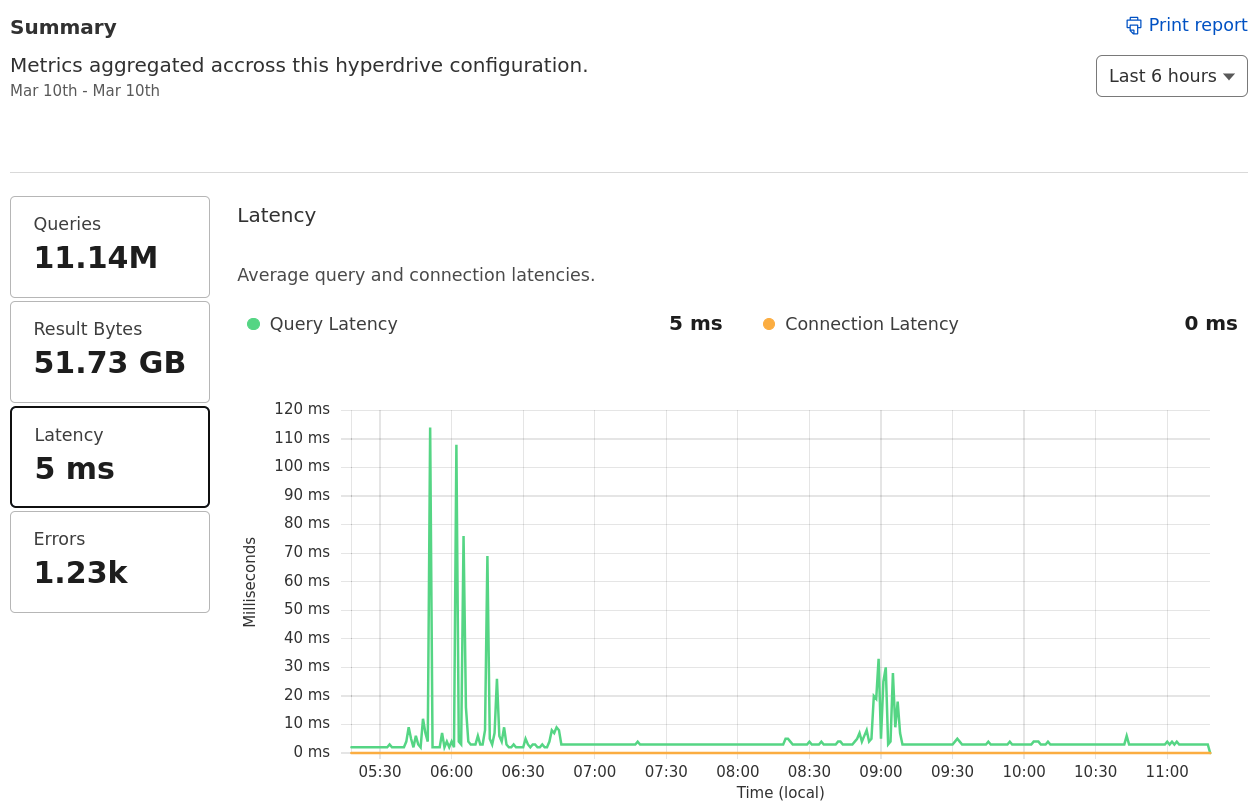
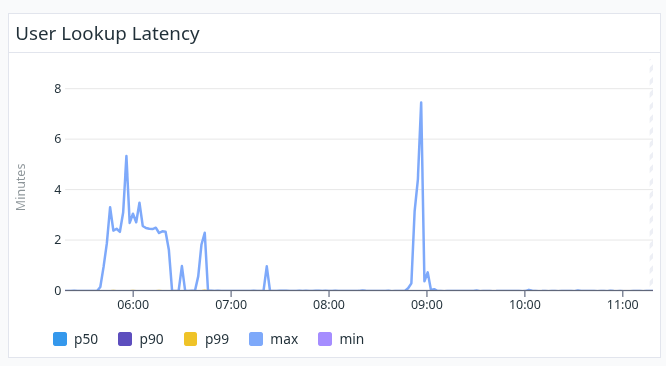 AAA
AAA I
I IAIA
IAIAstatement_timeout L
L
 BAA
BAA KAS
KASsetTimeout(cache.get(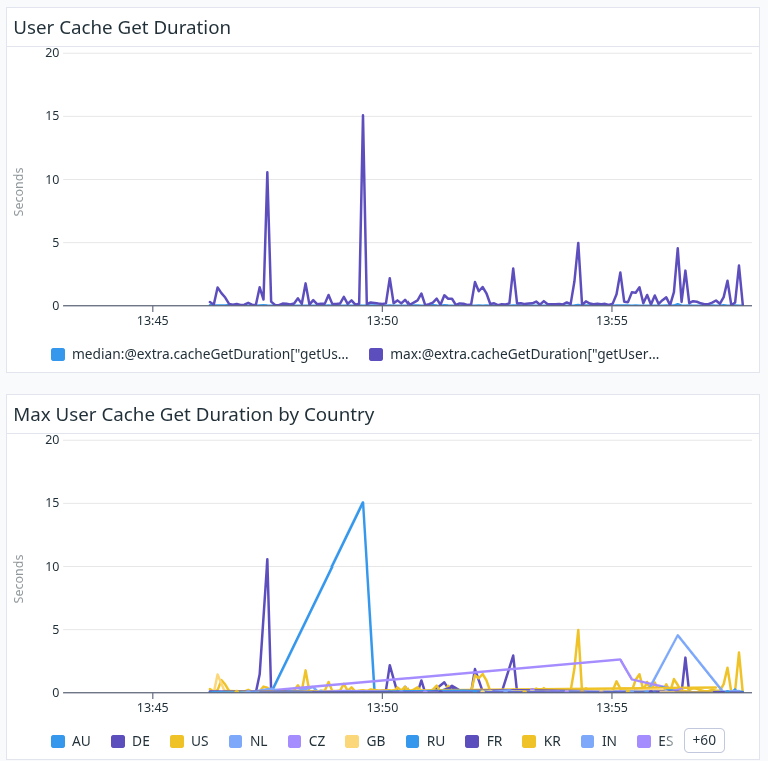
 DA
DA N
NError: write CONNECTION_CLOSED [some value].hyperdrive.local:5432cloudflared tunnel diag NA
NA C
Csql() V
Vfetch_types V
Vjsonb KAAAVVAAAVVV
KAAAVVAAAVVV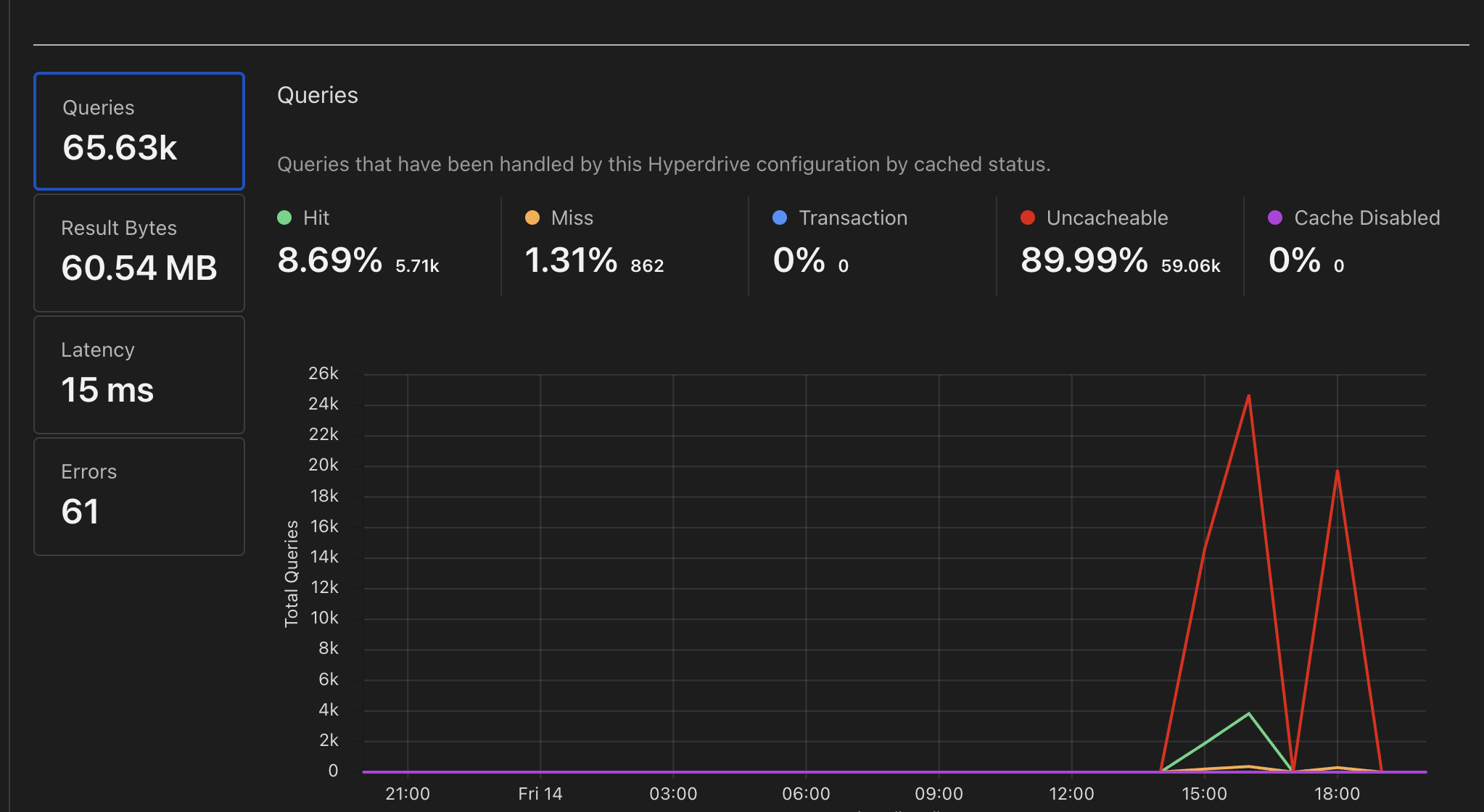 VK
VK K
K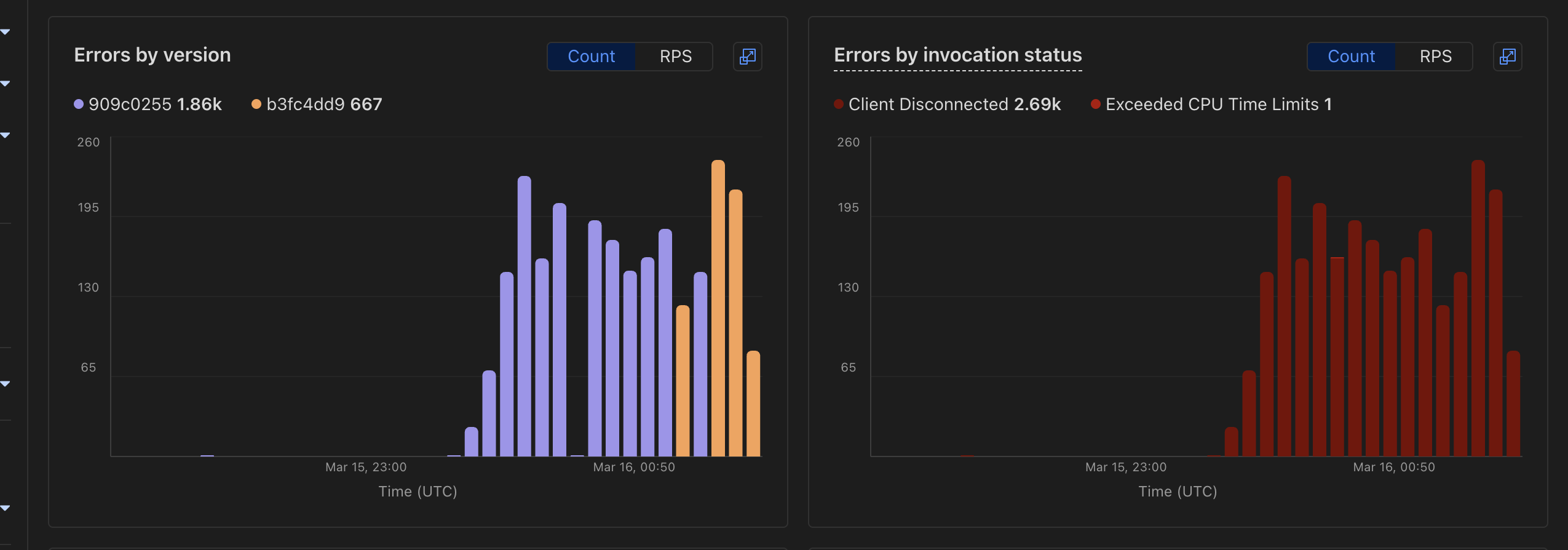 K
K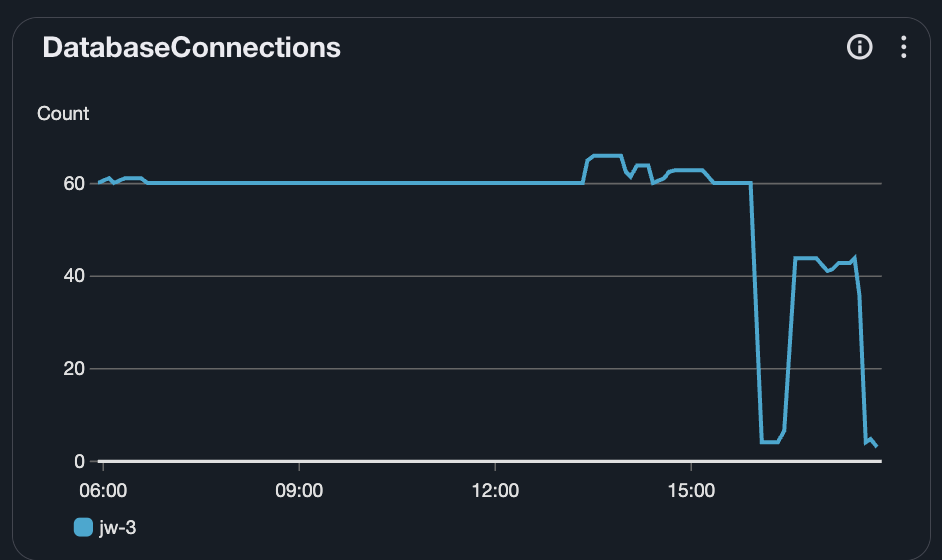
export function createDbConnection(databaseUrl: string) {
const sql = neon(databaseUrl);
return drizzle(sql, { schema });
}export function createDbConnection(hyperDrivedatabaseUrl: string) {
client = postgres(hyperDrivedatabaseUrl,{
max: 1,
fetch_types: false,
},);
return drizzle(client, { schema });
}








