I do seem to get back some data as screenshot response but it isnt base64 or a buffer that is valid
I do seem to get back some data as screenshot response but it isnt base64 or a buffer that is valid image. What am I doing wrong?
 S
Sbrowser_rendering but that results in a 400. The wrangler source code uses "browser": https://github.com/cloudflare/workers-sdk/blob/main/packages/wrangler/src/deployment-bundle/create-worker-upload-form.ts#L470-L471
 TTT
TTT
 J
JPDFOptions https://pptr.dev/api/puppeteer.pdfoptionsTJPDFOptions for that pdf endpoint at some point F
F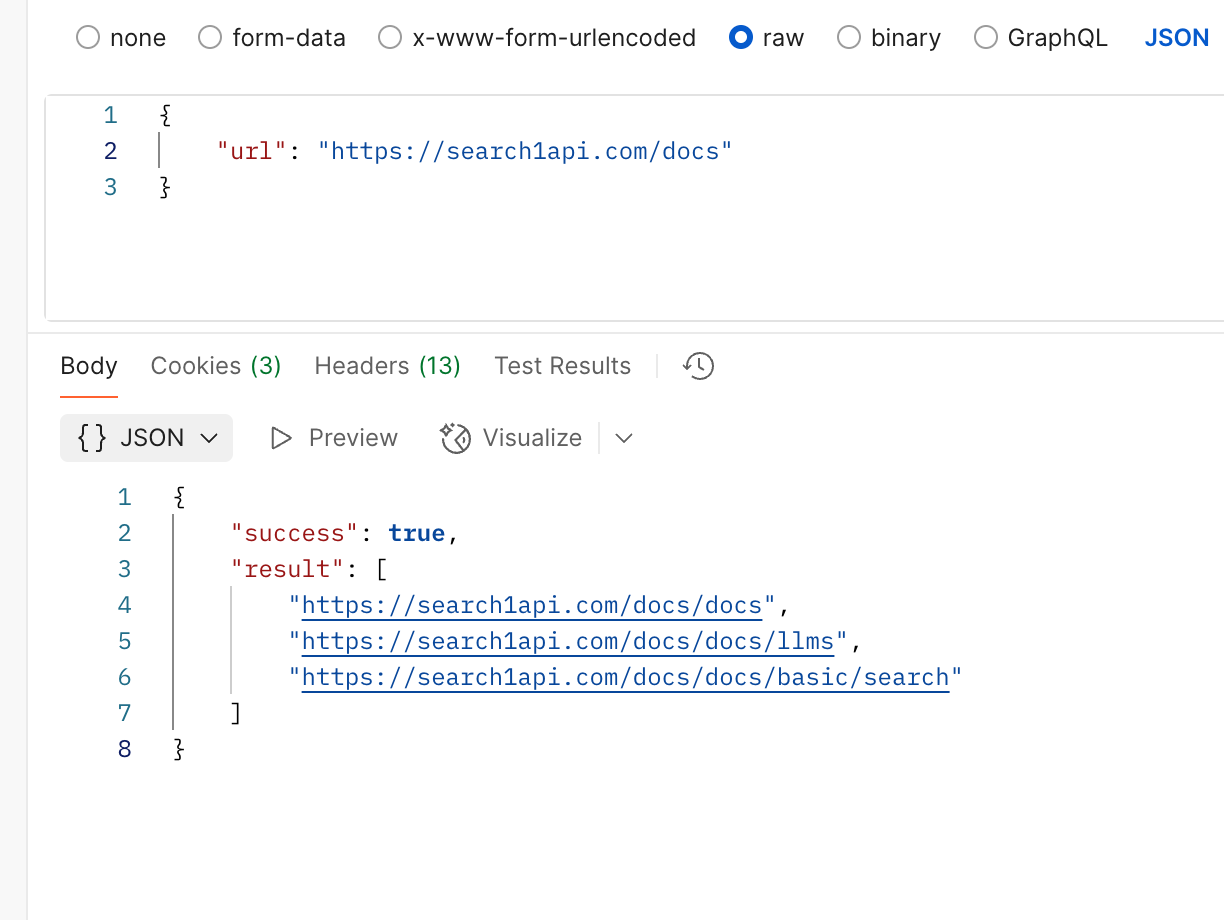 FT
FT TFF
TFF KKKTKF
KKKTKF M
M C
C C
C/markdown, then immediately after do a /scrape call to get the title element, will that generally have to re-scrape or can it pull from the cache? AFC
AFC{result: [{ results: [{ ... }] }]} not {result: {result: {}}}Curlhtml provided from /content of scraping that url and it doesn't work  CCKKK
CCKKK MCR
MCR AA
AA
 M
M SSS
SSS
 MM
MM VVM
VVM C
C HRK
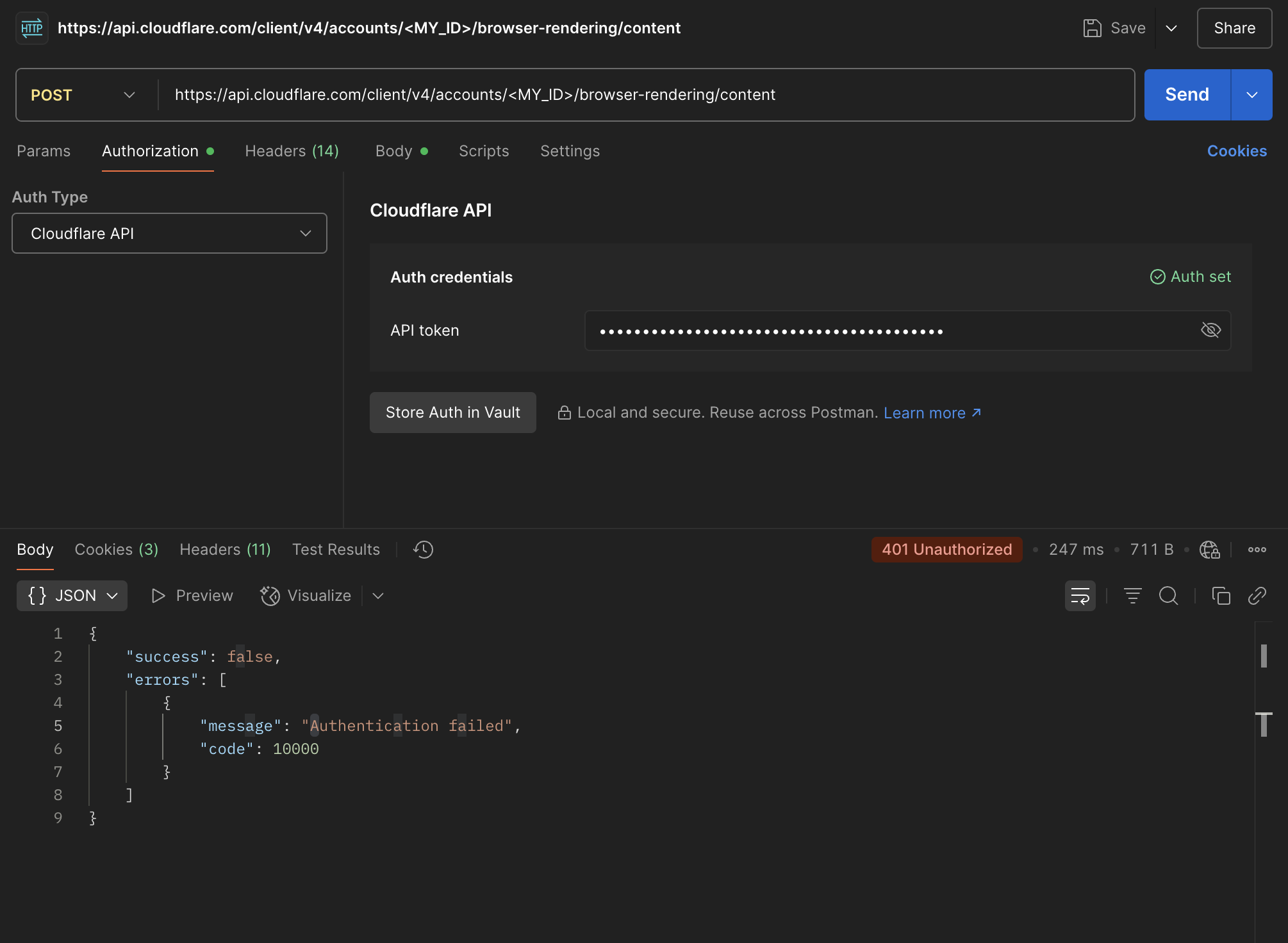
HRKbrowser_rendering400"browser"PDFOptionsPDFOptions/markdown/scrape{result: [{ results: [{ ... }] }]}{result: {result: {}}}html/content




