 F
Fit can be easily reproduced

 K
Ki'm able to reproduce. have reported bug to team
 K
Kwe've got something in the works that should fix this month. please hold tight
 K
Kthanks for the feedback @John Spurlock and @Tobias . will discuss with the team. aret here any other params you would expect to be included in the simple endpoints?
 T
Tthis is the only one i noticed so far, not used anything else
 K
Klooking into this
Fthanks!
 M
MHello Everyone, I am getting error Unable to regenerate API key. Invalid password
For Workers & Pages, what is the name of the domain?
NA
What is the error number?
1071
What is the error message?
Unable to regenerate API key. Invalid password
What is the issue or error you’re encountering
Trying to get the global API to work with the Cloudflare API, but while clicking on view, it asks for the password, which I don’t have, as I have logged in using Google auth
What steps have you taken to resolve the issue?
I tried adding the custom API as a password at that time, but it started giving this error.
For Workers & Pages, what is the name of the domain?
NA
What is the error number?
1071
What is the error message?
Unable to regenerate API key. Invalid password
What is the issue or error you’re encountering
Trying to get the global API to work with the Cloudflare API, but while clicking on view, it asks for the password, which I don’t have, as I have logged in using Google auth
What steps have you taken to resolve the issue?
I tried adding the custom API as a password at that time, but it started giving this error.

 C
CYou can logout and use the "Forgot your password?" option on the login screen, to get it set and then generate it
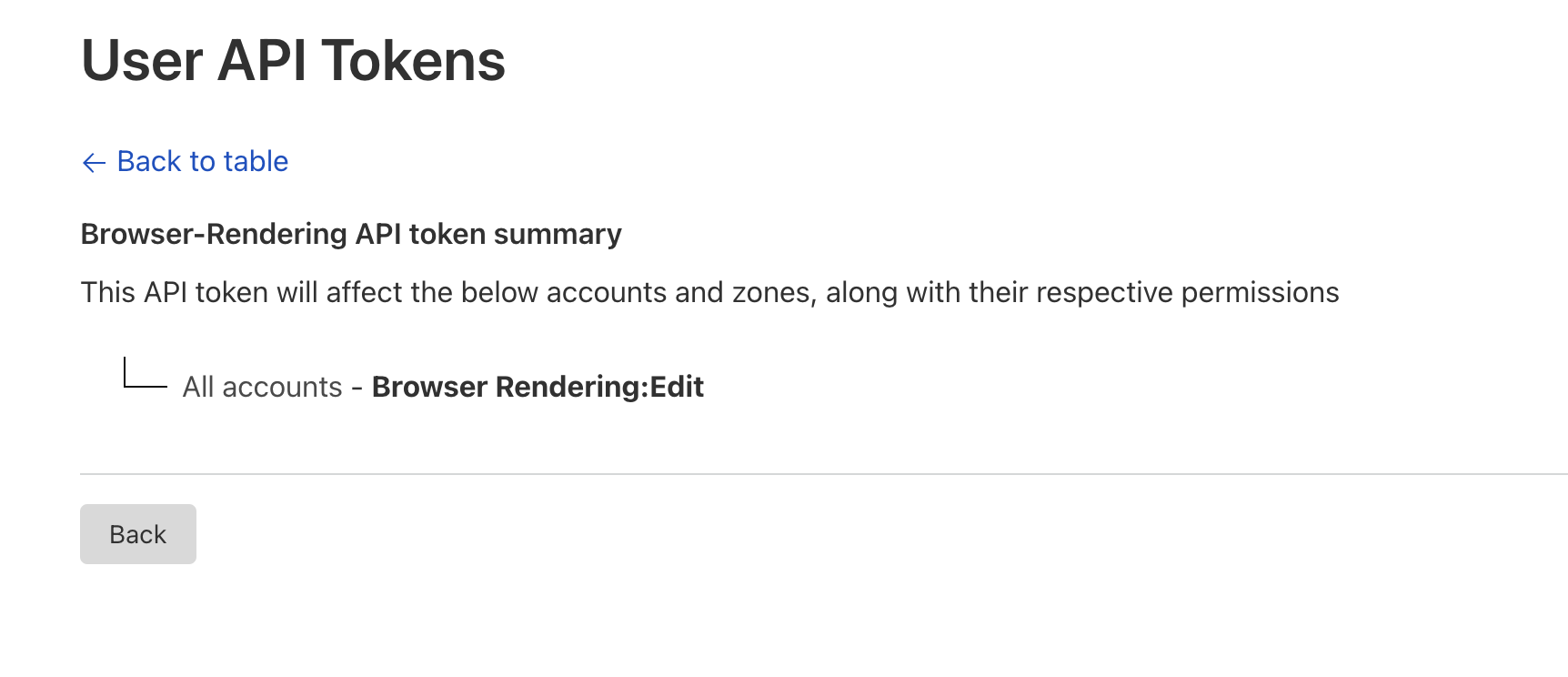
Using Global API Key isn't recommended though, scoped api tokens are more secure
Using Global API Key isn't recommended though, scoped api tokens are more secure
 C
Chey, any idea how the caching works for the REST API? IE: If I do a call to
/markdown, then immediately after do a /scrape call to get the title element, will that generally have to re-scrape or can it pull from the cache? A
Ajust checking in on this after a while... did the weird as heck billing ever get sorted out with this?
Fhey, Kathy, this issue has not been fixed yet. I think it is a bug obviously, when will your team fix this.
Chey guys, your docs are messed up for the scrape endpoint. https://developers.cloudflare.com/api/resources/browser_rendering/subresources/scrape/
The result shape is
The result shape is
{result: [{ results: [{ ... }] }]} not {result: {result: {}}}Interact with Cloudflare's products and services via the Cloudflare API
CAnother serious issue. Links endpoint works with 
url, but pass in the html provided from /content of scraping that url and it doesn't work CAnother thing... I would really like to be able to get the title of the page, I'm not sure if scraping for the title element will be good enough for SPAs... I tried to do this by injecting a script that would create a new dom element with document.title content in it but that didn't seem to work.
CRunning into this as well
Kit's in progress. hopefully fixed tmrw
Kwhat do you mean? we have not yet started charging, however we have raised limits in the meantime and added browser rendering to workers free
 K
Kthanks for raising these bugs + feature request.
 M
MHi, I am evaluating browser rendering API for an AI agent with browsing capability and persistent session (logged in user). Is this a good solution? (I also looking at Browserbase)
CI'm receiving a ton of 429s, any chance I can get some help raising the rate limits? I'm happy to do a user interview call too with our use cases or if you're thinking through pricing
Rhello
We have a issue with puppeteer setUserAgent
we do a classical await page.setUserAgent(userAgent);
but the navigator.userAgent always returns Cloudflare-Workers, ignoring what we used. Is that expected, a known issue or something?
This is blocking us for leveraging the browser api properly since sites we analyze recognize this fact and respond differently.
We have a issue with puppeteer setUserAgent
we do a classical await page.setUserAgent(userAgent);
but the navigator.userAgent always returns Cloudflare-Workers, ignoring what we used. Is that expected, a known issue or something?
This is blocking us for leveraging the browser api properly since sites we analyze recognize this fact and respond differently.
 A
AHello. Why i'm getting: {"error":"Unable to create new browser: code: 429: message: Browser time limit exceeded for today"}, i bought worker paid plan to avoid this...
ANo responses? 
 M
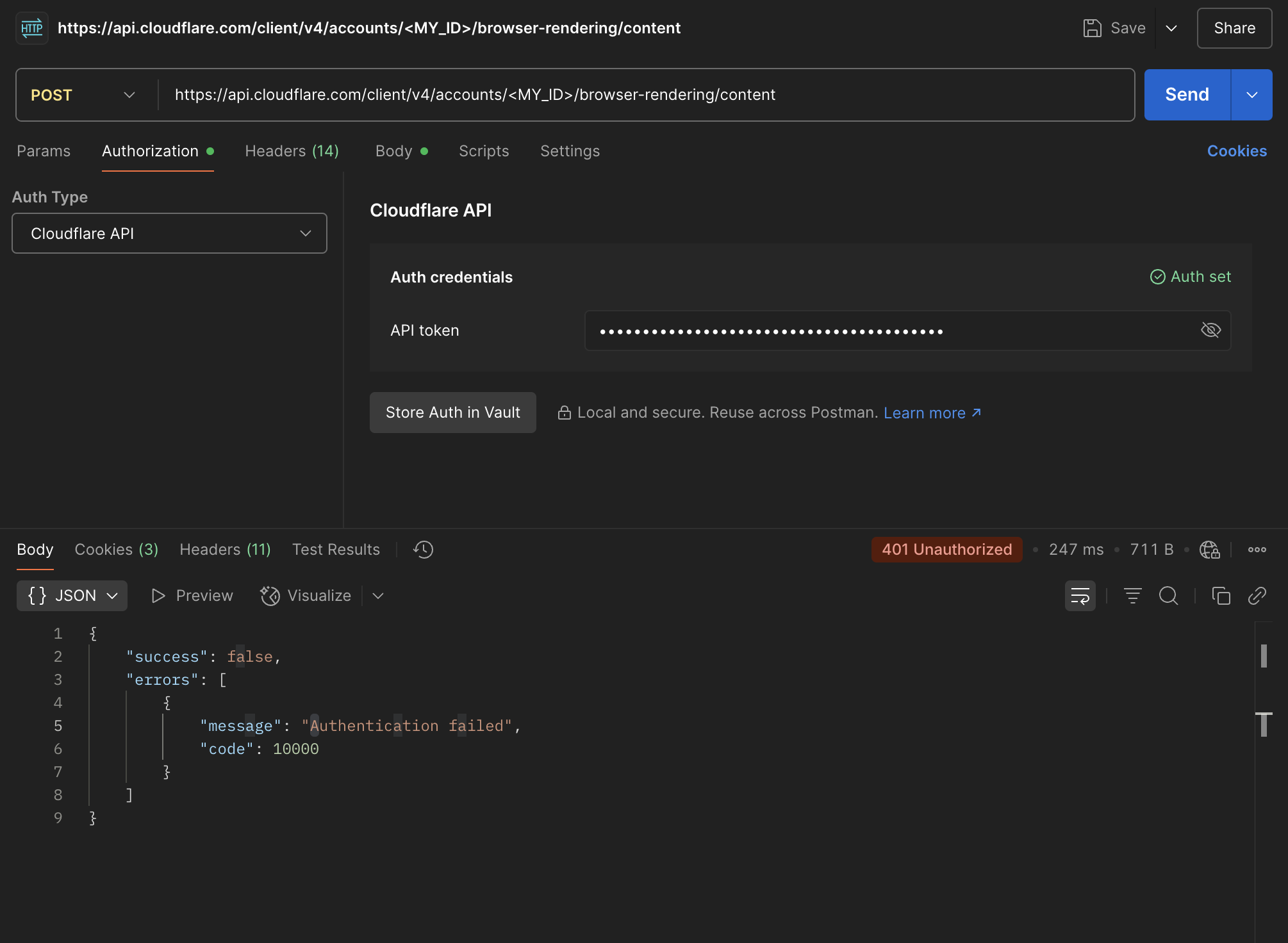
MHello , I have issue when I using Browser rendering restfull api , I want to render url to pdf , first requests it works fine , then all request return this error "{"success":false,"errors":[{"message":"Authentication failed","code":10000}]}" the api token is valid and has permission on browser rendering
 S
Sexactly the same issue
not sure why
not sure why
Si tried account and user both the tokens as well
Stried with "Bearer Token" as well
am i doing anything wrong here?
am i doing anything wrong here?
 M
MI think there an issue with cloudflare
Mbut if you found any resolve to this issue mention me
 V
Vit was related to this incident that has been resolved already https://discord.com/channels/595317990191398933/895794943182909470/1374043585124630591
Vplease let me know if you still have issues
Myes , it works now
 C
CNope! Moved away from using CF rendering.
 H
HHey CF team. I'm having trouble using the Browser Rendering binding in one of my workers to render a PDF of a web page. This was previously working ealier this month, but now the page.createPDFStream method is not returning a stream. Using page.pdf returns "Cannot create buffer". Any ideas on what would cause this?
RHello everyone, what is the best way to increase the rate limit on the browser rendering rest api? My account is set to startup/enterprise, so I assume it is configured to the default (60 r/min). We don't use this API constantly; however, when we do, we will have spikes in our usage for a short time, then it drops back to zero (it might increase later on) (unfortunately, our workflow is triggered by demand, and we can't schedule them in advance).
Kwe are checking on this. thanks for reporting
Kif you are on a paid plan, you can request higher limits here https://developers.cloudflare.com/browser-rendering/platform/limits/#workers-paid.
we ask that you only submit reqest if you're actively hitting limits as increasing limits requires manual action at this time and we want to prioritize customers who truly need the additional capacity. We're working on raising limits for everyone across the board, so this will become less of an issue in the future
we ask that you only submit reqest if you're actively hitting limits as increasing limits requires manual action at this time and we want to prioritize customers who truly need the additional capacity. We're working on raising limits for everyone across the board, so this will become less of an issue in the future

 M
Mhey team - do you plan to remove this limitation?
I dont want to run my entire project in remote just because of this browser binding :/
I dont want to run my entire project in remote just because of this browser binding :/
 K
Kyes support for local dev is coming up soon. totally understand that pain
 K
K^Also curious about this. Loading pages like stripe.com just result in a white screen, presumably due to a lack of GPU rendering.
 K
Kwould love to learn more about this ask. would you be open to a chat? https://calendar.app.google/DRNUac33bytqfzjj7
@kyle too
@kyle too
 K
KDefinitely!
KAlso more generally, want to learn more about everyone's use case and how browser rendering can help. So if anyone would like to speak please schedule here! https://calendar.app.google/DRNUac33bytqfzjj7
 R
RVery quick question before I spend sometime looking into this, I generate images from my worker app as react components, css/html. I’m using puppeteer to take screenshots of the component and turn them into .png. Can I incorporate this instead of puppeteer? Or is it as well as puppeteer?

 U
UGreat suggestion! Using
@vercel/og via Cloudflare Pages Functions is definitely faster and more efficient than browser-based rendering, perfect for generating dynamic PNG/SVG from React components at scale.R@Luney @U.Senthil Kumar | Contributor I fully agree with vercel og/satori , in fact I used it originally when I was using vercel, before I decided to go down the cloudflare route. I might re look at it, as I was coming up with some issues passing in the component, it would defo be better,