workers-and-pages-help
pages-help
general-help
durable-objects
workers-and-pages-discussions
pages-discussions
wrangler
coding-help
kv
🦀rust-on-workers
miniflare
stream
general-discussions
functions
zaraz
⚡instant-logs
email-routing
r2
pubsub-beta
analytics-engine
d1-database
queues
workers-for-platforms
workerd-runtime
🤖turnstile
radar
logs-engine
cloudflare-go
terraform-provider-cloudflare
workers-ai
browser-rendering-api
logs-and-analytics
next-on-pages
cloudflare-ai
build-caching-beta
hyperdrive
vectorize
ai-gateway
python-workers-beta
vitest-integration-beta
workers-observability
workflows
vite-plugin
pipelines-beta
containers-beta
Large File Convertion
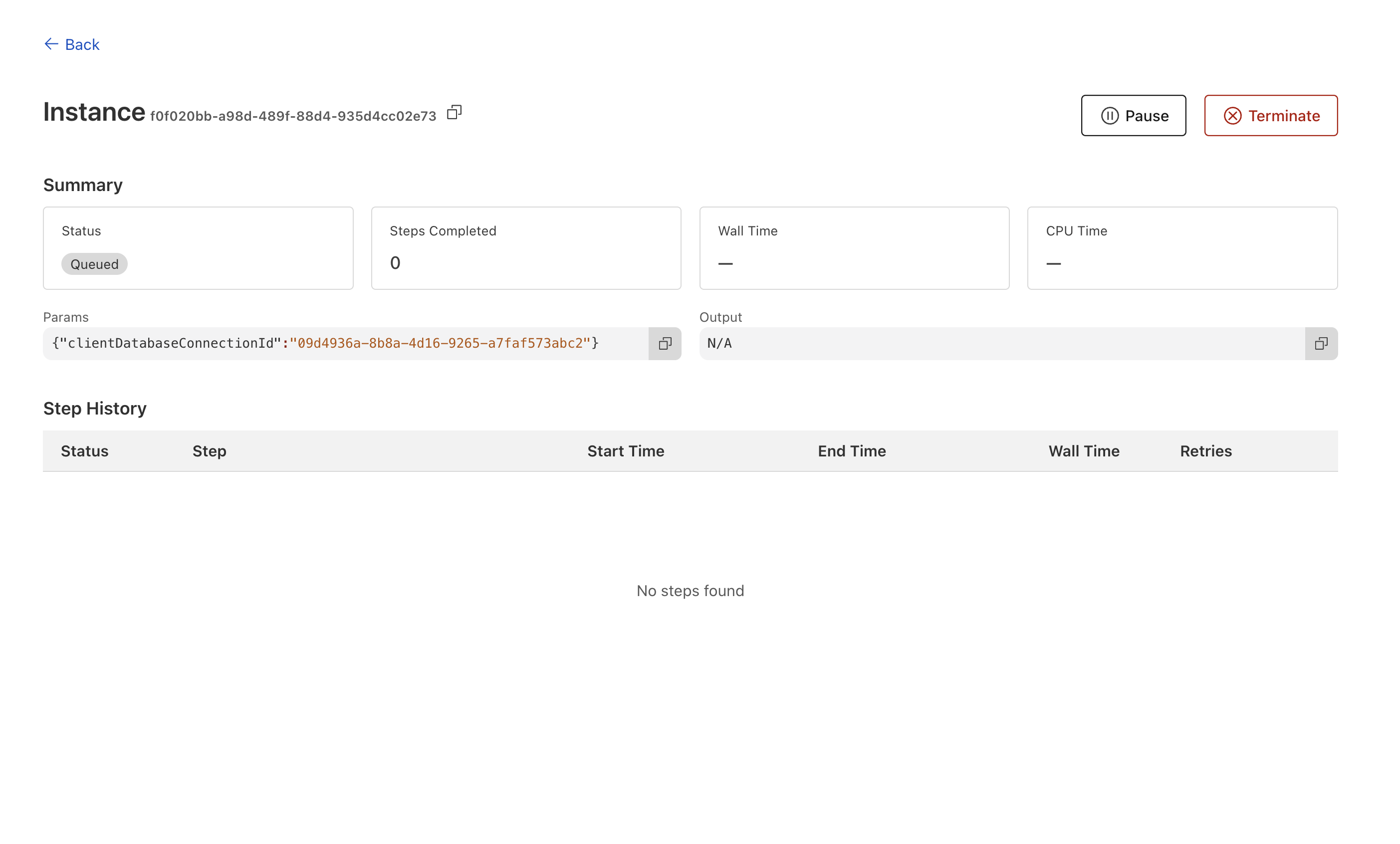
Is there anyone faces invalid instance
Hey 👋
WorkflowInternalError: Attempt failed due to internal workflows error errors - at any step (even those that weren't affected by my latest deploy).
Run ID: 6b8af9a0-7ba7-4f2a-ade4-31500c2b2cfb, 0ecea869-a90e-416f-a882-2a84f45d7f13, or 5ba45a09-a860-4f7c-8097-197b67dbfbf0. ...Workflows stuck QUEUED
Blocked cron
cron it seems to do it from other geographic locations. I have a security rule to block all traffic to the worker that's not from the United States and it seems that, as of recently, my cron-scheduled workflows are being instantiated outside of the United States in Poland or Singapore which is causing them to be blocked by the security rules.
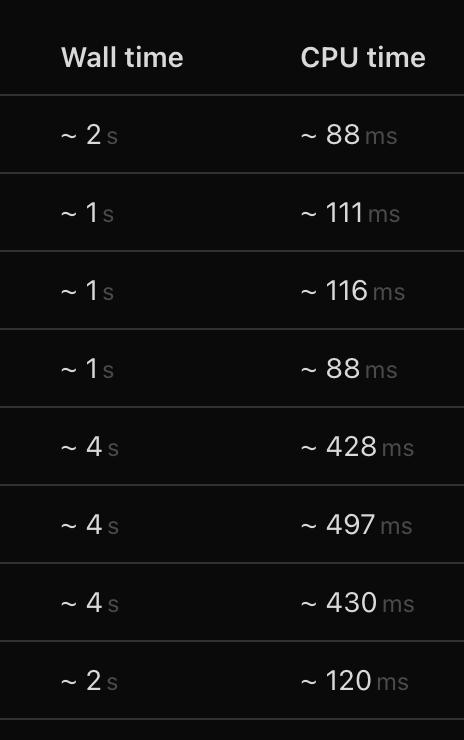
Is there a way to force location of execution of workflows or whitelist / exempt same account workers from security rules?...Why workflows have such a big wall time
`introspectWorkflow` _should_ be done at
introspectWorkflow should be done at the start of the test (you can think of doing introspectWorkflow where you mock other APIs and so on) - intercepted workflows with DOs should just work (if you want to mock/intercept the calls between the two, let me know)Greetings, having the same issue as some
Greetings,
Hey, I got errors like instance.not_
env.WORKFLOW.get(instanceId)
env.WORKFLOW.get(instanceId)
Found a bug in making workflows. Despite
I'm getting the following error for my
Error: Aborting engine: Grace period complete
Error: Aborting engine: Grace period complete
In terms of UX, that would be great to
Hi, any workflows we create are giving
Internal Server Error, and we can't view our Workflows in the dashboard. Any incidents going on?
We are having an issue where one of our
Complete with Error?
createBatch user provided ids
I would be interested how you use DOs to